Abstract
Land Cover (LC) maps offer vital knowledge for various studies, ranging from sustainable development to climate change. The China Central-Asia West-Asia Economic Corridor region, as a core component of the Belt and Road initiative program, has been experiencing some of the most severe LC change tragedies, such as the Aral Sea crisis and Lake Urmia shrinkage, in recent decades. Therefore, there is a high demand for producing a fine-resolution, spatially-explicit, and long-term LC dataset for this region. However, except China, such dataset for the rest of the region (Kyrgyzstan, Turkmenistan, Kazakhstan, Uzbekistan, Tajikistan, Turkey, and Iran) is currently lacking. Here, we constructed a historical set of six 30-m resolution LC maps between 1993 and 2018 at 5-year time intervals for the seven countries where nearly 200,000 Landsat scenes were classified into nine LC types within Google Earth Engine cloud computing platform. The generated LC maps displayed high accuracies. This publicly available dataset has the potential to be broadly applied in environmental policy and management.
Background & Summary
Land Cover (LC) changes influence most natural and physical processes on Earth, such as the hydrological cycle, ecological balance, and ecosystem services1,2. Understanding LC types and their changes over time at different spatial scales, from regional to global, is of paramount importance for multiple disciplines, such as environmental risk assessment, global warming, and sustainability3,4. Remote Sensing (RS) data, with its varying spatiotemporal resolutions, has become an essential tool for monitoring LC changes5,6. Despite the tremendous efforts that have been conducted in the LC change mapping field, accurate knowledge on historical LC changes over large areas is still limited7,8.
A key part of the Belt and Road Initiative (BRI) program, the China-Central Asia-West Asia Economic Corridor (here after referred to as the Corridor) encompasses eight countries (China, Kyrgyzstan, Turkmenistan, Kazakhstan, Uzbekistan, Tajikistan, Turkey, and Iran) that mostly are situated in arid and semi-arid climates9. Over the last decades, the Corridor has been impacted by some of the world’s worst LC change tragedies9. The Aral Sea crisis and Lake Urmia shrinkage are two main examples in this regard. More specifically, the Aral Sea in Central Asia has lost over 80 percent of its surface over the past few decades10, and Lake Urmia in Iran has similarly shrunk in surface area by 80 percent between 2005 and 201511. Given that those kinds of severe LC changes can threaten lives of millions of humans and species12,13,14 the precise long-term LC dataset along the Corridor is therefore essential for understanding the main causes of such changes.
A number of high to coarse resolutions global LC products, such as FROM-GLC15, GlC200016, and MODIS17 datasets have been generated by the RS community. However, the existing LC products have limited applicability for a variety of long-term LC change monitoring applications due to their narrow temporal coverage, relatively low accuracies, and inconsistencies in the classification systems among different global LC products7,9. For example, although the Globland30 dataset is indeed a valuable product, theses dataset is only available at decadal intervals (2000, 2010, and 2020). It is also impractical to use this LC dataset as a benchmark for long-term LC change monitoring aim due to its unknown accuracy for 2000 and relatively low accuracy in certain regions, such as Central Asia where Sun et al.18, indicated a low Overall Accuracy (OA) of 46 percent. Similarly, Naboureh et al.19, claimed that Globland30 had a relatively low OA of 62.3 percent for Turkey. Thus, it is impractical to study historical LC changes using the available LC products.
Addressing this deficiency, the Landsat archive’s free sharing policy in 20082,20 and the advent of Earth science data cloud computing and analysis tools, such as Google Earth Engine (GEE), have facilitated the production of various types of LC products19. As a result, several valuable LC datasets for various regions of the world have been generated. For instance, Calderón-Loor et al.7, generated a set of seven 30-m resolution LC maps covering the period of 1985–2015 at five-year intervals. In another attempt, Pekel et al.21, generated annual global surface water area dataset from 1984 to 2016. However, our team’s review9 revealed that a long-term LC dataset is still lacking for the majority of the Corridor, including Kyrgyzstan, Turkmenistan, Tajikistan, Uzbekistan, Iran, and Turkey. To the best of our knowledge, the only exception is China, where Yang and Huang5 created the first 30-m annual LC dataset spanning the period between 1990 and 2019, based on the GEE platform and Landsat data.
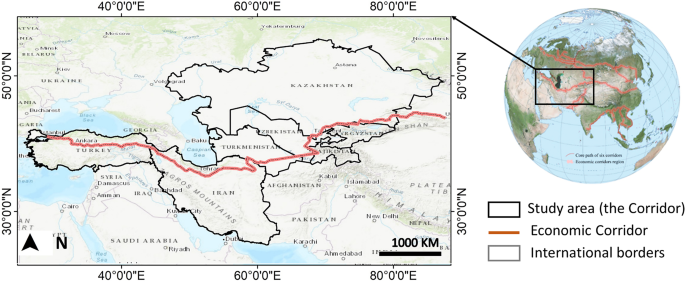
This paper presents a set of six 30-m resolution LC maps for seven countries from the Corridor, excluding China, namely Kyrgyzstan, Turkmenistan, Tajikistan, Uzbekistan, Iran, and Turkey (Fig. 1). To generate these maps, we utilized all available surface reflectance Landsat data from 1990 to 2020 through the GEE platform. Furthermore, we compared the generated LC maps against the available scientific LC products to ensure the accuracy of the results. The generated dataset is the first-of-its-kind for one of the BRI’s Corridors, filling a significant knowledge gap in the region. The dataset provides valuable information to policymakers, enabling them to make informed decisions on land use/cover management, environmental planning, and sustainable development in the region.

The location of the study area.
Methods
This study offers a set of six 30-m LC maps for the seven countries from the Corridor between 1993 and 2018. The entire procedure was carried out on the GEE cloud processing platform (Fig. 2) that allowed us to derive pixel-wise analysis while bypassing the need for data download. The analysis was performed in 5-year epochs (1991–1995, 1996–2000, 2001–2005, 2006–2010, 2011–2015, 2016–2020). We created one LC map for per epoch (six LC maps in total); for instance, the 1993 LC map represents the 1991–1995 epoch. As shown in Table 1, the generated LC map at each time step includes nine LC classes: Bare land, Built-up, Shrub lands, Forest, Cropland, Grassland, Wetland, Snow/Ice, and Water. In general, the study consisted of six main steps (Fig. 2): 1) Study area subdivision, 2) Satellite data acquisition and pre-processing, 3) Input features generation, 4) Reference sample data collection, 5) Supervised classification, and 6) Accuracy assessment.

Main flowchart of this study.
Study region subdividing
This study focuses on five Central-Asian countries (Turkmenistan, Uzbekistan, Kyrgyzstan, Tajikistan, and Kazakhstan) and two West-Asian countries (Turkey and Iran), with a total area of about 6,435,208 km2. The large area covered by the study area includes a wide range of climate zones, from cold-desert climate to hot-semi-arid climate, which can lead to significant intra-class variability of spectral signatures of the same LC type and potentially reduce LC classification accuracy. On the other hand, large-scale studies require an immense size of input features, making processing of the entire region often unfeasible22. Our recently published research19 has shown that adopting an adaptive classification approach that divides the large-scale region into several sub-areas can effectively address these issues. As such, we divided the Corridor region into 25 sub-areas identified by Köppen-Geiger climate classification system23 (Fig. 3). It’s worth noting that we combined similar classes due to the presence of small detected zones. Furthermore, to avoid processing timeouts, certain regions were divided into two or three sub-areas. The Köppen-Geiger integrates the mean yearly and monthly temperatures and rainfall and seasonal rainfall to divide the study area into fairly homogeneous zones. The main advantages of this approach are twofold: it allowed us to bypass “user storage limited” and “computational time out” limitations of the GEE platform, while also decreasing the effect of climate variation on LC classification success.

(a) Köppen-Geiger climate classification for the study area. (b) Location of introduced sub-areas.
Satellite data acquisition and pre-processing
Since the lunch of Landsat-5 in 1984, Landsat satellites (TM, ETM+ , and OLI/TIRS) have been offering 30-m Earth observation data, which is widely known as an ideal source for LC mapping over large areas7,9. In this study, all the available surface reflectance Landsat data between 1st January 1991 and 31st December 2020, were acquired within the GEE cloud processing platform, as there were not adequate Landsat scenes covering the entire study area during 1984–1990 (Fig. 4a). A total of 194,155 Landsat scenes were obtained, including 70,339 Landsat-5, 82,770 Landsat-7, and 41,046 Landsat-8 images, to generate LC maps for the years 1993, 1998, 2003, 2008, 2013, and 2018 (Fig. 4c). To mitigate missing data and cloud interference and, a stack of Landsat scenes for the target year ± two years was created at each time-stack (e.g., times-series of Landsat-7 scenes from 1991 to 1995 were utilized to create the year 1993 mosaic), where each stack contained at least 5 valid observations at pixel-level. The FMASK algorithm24 was then applied to eliminate unwanted pixels, such as cloud and cloud-shadows.

(a) Distribution of available surface reflectance Landsat −5 images for the years 1985, 1986, 1987, 1988, 1989, and 1990. (b) Observation counts from surface reflectance Landsat-8 across the study area to generate the year 2018 mosaic (1st January 2016 to 31st December 2020). (c) Number of the processed surface reflectance Landsat images in this study per year.
Input features generation
Six bands from Landsat data, including Short-wave infrared 1, Short-wave infrared 2, Near-infrared, Green, Blue, and Red were utilized in this work. Moreover, using the Random Forest (RF) variable selection technique, eight spectral indices were calculated among various spectral indices to contribute in LC mapping (Table 1). As shown in Table 1, along with those spectral bands and indices, bioclimatic variables (mean annual temperature and annual precipitation) and topographical features (elevation, slope, and aspect) were also created and added to the cloud-free stacks. The topographical features were taken from the Shuttle Radar Topography Mission (SRTM) data, and the bioclimatic variables were obtained from the WorldClim25 data. Using the nearest neighbour interpolation method, all auxiliary variables were resampled to 30-m pixels in accordance with the Landsat pixel grid. Finally, a mean function was applied to all cloud-free stacks at each time step to generate a single mosaic image for classifying each LC map.
Reference sample data collection
We used three different techniques to collect high-quality reference samples for calibration and testing. The first method used was the Semi-automatic High-quality Reference Sample Generation method (HRSG) developed by our team19. This method acknowledges that no scientific LC product/map can be entirely free of errors, and a limited number of training samples are capable of representing intra-class diversity. Consequently, the HRSG method acquires the identified pixels of the target LC type from the existing LC products, then implement the linear spectral unmixing analysis to obtain samples for the target class. In this study, a wide range of existing LC products, such as GlobLand3026, GLC-FCS3027, MCD12Q117,Global Artificial Impervious Area (GAIA)28, and JRC global surface water21, were used to obtain reference sample datasets for nine LC classes at five different time-steps (Table 3).
In order to ensure an adequate number of samples and a diverse representation of each LC class (random sampling technique), the visual interpretation technique was used when the collected samples by HRSG method was insufficient. The study aimed to have at least 30,000 training samples at each time step to achieve acceptable accuracy according to the conducted initial experiments. Therefore, samples were obtained using Landsat images, annual NDVI time series, and the Google Earth images. More specifically, following Naboureh et al.19, the samples were first collected using Google Earth (publicly available fine spatial resolution images) and Landsat images. Then, their annual NDVI time series were extracted from Landsat images. Finally, the true label was determined for an LC class if the NDVI values of the given sample was stable over each time step.
Additionally, the available high-quality samples generated by RS community was used in this study. One such example is the cropland data in Central Asia, which has been provided by Remelgado et al.29, Their dataset includes a total of 8,196 samples collected between 2015 and 2018, as well as 213 samples from 2011 and 26 samples from 2008. We double checked these samples, and stable samples were added to the generated dataset for 2013 and 2018. Overall, the final dataset for each time interval includes over 50,000 pixel points (Table 4) that is split into a training (70%) and validation (30%). Table 4 presents the proportion of samples for each LC type in 2018.
We conducted initial experiments to eliminate the possibility of discontinuous classification results near climatic zone boundaries, as reported by Shafizadeh-Moghadam et al.22, We observed instances of sudden fluctuations occurred near climate zone boundaries when the distribution of training samples was not well-balanced. To address this challenge, we adopted a rigorous technique to ensure that training samples are evenly (to the greatest extent possible) distributed across all sub-areas. This not only improved the model’s ability to generalize in diverse regions but also lowered the risk of discontinuous classification results across climatic zone boundaries.
Supervised classification
There is a broad selection of supervised LC classification algorithms available, such as neural network, maximum likelihood classification, support vector machine, extreme learning machines, and RF. However, there is no final recognition on introducing a single classifier that offers the most precise outputs in all landscapes and circumstances yet because the given model setting and environmental conditions vary among different study areas9,30. RF has become a popular choice for large-scale LC classification due its ability to handle complex and high-dimensional data31. An investigation, which focused on six different landscapes in the Corridor, found that RF had the best performance among several well-known supervised classification algorithms32. In addition, our research19 revealed that using an adaptive RF-based classification method can effectively address the impact of climate variations on LC classification accuracy. Consequently, to create LC maps for the years 1993, 2003, 2008, 2013, and 2018, this study utilized an adaptive RF classification scheme. The study region was separated into 25 sub-areas (as shown in Fig. 3), and a separate RF classifier was developed for each sub-area. The results of each sub-area were then combined to create the ultimate LC map for each time interval. It is worth mentioning that after testing various tuning settings, we found that adjusting the number of variables and decision trees to the square root of the number of variables and 250, respectively, yielded the best results.
Accuracy assessment and comparison against existing LC products
We evaluated the produced LC maps using the confusion matrix to calculate three commonly used accuracy metrics: OA, F1-score, Producer Accuracy (PA), and User Accuracy (UA). In general, we used minimum 15,000 validation samples at each time interval for assessing the produced LC maps. We also used a visual interpretation technique to ensure the generated LC maps are noise free, particularly across climate zone boundaries, where sudden fluctuations can be noticed if the distribution of training reference samples is poor. Additionally, taking the year 2018 as an example, we compared the generated LC map in this study against GlobLand30 (30-m resolution) and Dynamic World33 (10-m resolution) products for a more comprehensive performance evaluation. To this end, the GlobLand30 version 2020 and Dynamic World version 2018 (time filter = between 1st January 2018 and 31st December 2018) products have been used in the comparison task. It should be noted that we focused on Turkey as testbed in this section. The reason for the selection of Turkey was twofold: Turkey encompasses different climate zones and elevation ranges, and, most importantly, there were available independent validation samples with a total of almost 6000 data points. It is worth mentioning that although the selected LC products share almost the same classification system, based on the classification system of this research (Table 5), we reclassified GlobLand30 and Dynamic World products.
Data Records
The generated data are accessible through National Tibetan Plateau Data center (https://doi.org/10.11888/Terre.tpdc.300482)34. This dataset consists of six land cover maps (1993, 1998, 2003, 2008, 2013,and 2018) for the Corridor region, which spans seven countries including Turkey, Iran, Kyrgyzstan, Kazakhstan, Tajikistan, Turkmenistan, and Uzbekistan. These LC maps include nine LC classes (see Table 1), and cover the time period from 1993 to 2018. This dataset34 is provided at a 30 m spatial resolution in TIFF format.
Technical Validation
To evaluate the generated map, we used visual interpretation, statistical accuracy assessment, and inter-comparison with existing LC products for a fair and comprehensive evaluation of the produced LC maps.
Visual interpretation and statistical accuracy assessment
The visual interpretation assessment method illustrated that the generated LC dataset34 for the years 1993, 1998, 2003, 2008, 2013, and 2018 are noise-free and offer reasonable depictions of all nine LC types (Fig. 5). Additionally, we used minimum 15,000 (randomly selected samples) ground trust samples to implement pixel-wise validation at each time step. To this end, we calculated OA, UA, PA, and F-1 score metrics, as indicator of the performance the generated LC maps. The average OA of the generated LC maps was 91.4%, with the highest OA of 92.7% observed in 2003 and the lowest OA of 90.3% in 2018 (Fig. 6b). The accuracy of the LC classes varied considerably (Fig. 6c). As shown in Fig. 6b, Water and Snow classes displayed the highest mean PA, UA, and F1-score values (>95%) for the generated maps, while the Grassland and Cropland had lowest mean UA, PA, and F1-score values (>85%).

An example of the generated land cover maps for the Corridor region (year 2018), and three zoomed areas (with different climate conditions and landscapes) of the LC map along with matching Landsat images (annual median compositions).

Accuracy assessment results for the generated land cover dataset. (a) Average user accuracy (UA), producer accuracy (PA), and F1-score accuracy per class; (b) Overall accuracy (OA) results at each time-step and average OA; (c) The PA and UA results for each land cover type at each time-step.
Inter-comparison with existing LC products
We compared the generated LC map in this study (the year 2018) against GlobLand30 and Dynamic World Products. To this end, because GlobLand30 is not accessible for 2018, the 2020 version of GlobLand30 product was used in this study. Moreover, the mean image (1st January 2018 to 31st December 2018) of Dynamic World in 2018 were obtained from GEE platform. As can be seen in Fig. 7, our map closely reflects the exact LC type in satellite scenes. Our visual assessment showed that the generated LC map also has good consistency with the GlobalLand30 product although the generated LC map in this study could distinguish Grassland, Water, Snow, and Wetland classes more precisely than the GlobLand30 product. For instance, Fig. 7a–c shows that GlobLand30 overestimates Grassland classes, and Fig. 7d illustrates an overestimation of the wetland class. The overall layouts of all nine LC classes were almost the same for the generated LC map in this study and Dynamic World. However, the produced LC map in this work outperformed this product in distinguishing Water and Snow classes. Our visual assessment showed that the Dynamic World product misclassified the dried lake’s bed (Fig. 7a,b) as snow class. Additionally, Dynamic World mislabelled clouds and cloud shadows as Water class (Fig. 7c). In contrast, Dynamic World could distinguish built-up class more precisely than generated LC map in this study that could be related to the higher spatial resolution (10-m) of input data for this product.

Comparison of the generated LC map of the year 2018 against GlobLand30 and Dynamic World products. The corresponding Landsat imagery are the annual median compositions of Landsat images in 2018 (1st January 2018 to 31st December 2018). The experiment sites are located (center location) at: (a) 38° 45′ 47″ N – 33° 21′ 03″ E; (b) 38° 05′ 48″ N – 45° 15′ 38″ E; (c) 30° 31′ 07″ N – 49° 07′ 33″ E; (d) 50° 23′ 42″ N – 69° 14′ 16″ E; (e) 41° 50′ 32″ N – 77° 22′ 21″ E.
We also applied a quantitative comparison between the results of the present work with the two LC products selecting Turkey as the experiment site. It was observed that the generated LC map in this study in 2018 achieving OA = 92% outperformed Dynamic World (OA = 70%) and Globland30 (OA = 60%) products. Except for water class (PA value) in Dynamic World, snow (UA value) and cropland (UA values) classes in Globland30, the obtained PA and UA values for all nine LC classes of the generated LC map in this study were higher than the other two LC products (Fig. 8). Overall, the generated LC map in this study showed high statistical and visual accuracies that confirms the necessary confidence in the reliability of generated LC dataset. It is crucial to highlight that even though both Globland30 and DynamicWorld products showed relatively low accuracies, the enduring value and knowledge offered by these two well-known LC products remain undeniable, delivering remarkable insights to the RS community.

Comparison in three accuracy assessment metrics among the generated LC map in this study for the year 2018 and Globland30 (2020 version) and DynamicWorld products.
Uncertainty analysis
We implemented an adaptive supervised classification scheme to accurately discriminate nine LC classes for a large-scale study. As shown in Fig. 7, our classification performed better for Snow, and Water classes whereas Grassland and Cropland classes presented a lower accuracies. We have found that the confusion between Cropland areas and Grassland/Shrub lands were common based on the conducted visual assessment. The higher accuracy for Snow and Water classes was reasonable due to their distinctive spectral response and the NDVI index’s high ability in extracting these classes. The main sources of lower accuracies for Grassland and Cropland classes could be related to: 1) spectral similarity among vegetation classes; 2) selection of ancillary variables; and, 3) Sensor limitation. Using different phonologically relevant periods and seasons (e.g., growing season) could improve the discrimination among spectrally similar classes (e.g., Cropland, Shrub land, and Grassland). However, we could not generate seasonal cloud-free Landsat data due to the lack of surface reflectance Landsat-5 data before 2000 and the issue of Landsat-7 before 2012. Different input features can greatly impact the classification results, and this study used the same nineteen variables (Table 2) as input features for the classification of 25 sub-areas at six different time steps based on the RF feature selection method. Utilizing more variables and adopting specific variables for each sub-area may lead to higher classification accuracy, but we have used a similar input feature in the classification tasks due to the input-feature limitation of GEE and the work’s time-consuming nature. The 30-m spatial resolution of Landsat data restricted the ability to distinguish LC types smaller than this scale, in particular small Cropland and Built-up areas. In general, the dataset34 is not error-free and the users should consider possible error/noise when interpreting the LC maps, but the generated LC dataset is reasonable.
Usage Notes
Accurate knowledge on LC types and their changes over time is critical for different research fields, such as ecological protection, environmental management, and sustainable development. LC datasets with high spatial and temporal resolution are critical for monitoring changes in land use, identifying patterns of deforestation and urbanization, and evaluating the impact of human activities on natural ecosystems. The generated LC dataset in this study with a 30-m resolution is the first of its kind for one of the BRI’s Corridor. This dataset provides a comprehensive picture of LC dynamic for seven countries in the region since 1993. The dataset has been meticulously validated to ensure its accuracy and reliability. This dataset can be included as part of the digital BRI program, which seeks to promote the use of science and technology for sustainable development of the BRI region. This dataset has multiple applications; for example, given the remarkable shrinkages in surface water area in the Corridor region14,21,35 over the last few decades, affecting the lives of nearly two billion people, this dataset can serve as a useful tool for analysing the dynamic of surface water changes in the study area (Fig. 9) and identifying the main driving factors. Additionally, the dataset can be used as a baseline for predicting future status of LC in the region, enabling us to make informed and strategic choices to mitigate the adverse environmental consequences of LC alterations in the region. By sharing this dataset, we can facilitate data-driven decision-making, promote transparency and accountability, and encourage collaboration among the BRI countries.

Application of the generated dataset for studying surface water changes in the region. Changes in surface water areas in two dying lakes during the 1993–2018 period: Aral Sea, Central Asia (center location = 45° 05′ 30″ N – 59° 28′ 23″ E) and Lake Urmia, Iran (center location = 37° 43′ 57″ N – 45° 21′ 40″ E).
Code availability
The used scripts to implement our adaptive classification scheme is available in the following link: https://github.com/AminNaboureh/Adaptive_LC_classification.git.
References
-
Arowolo, A. O., Deng, X., Olatunji, O. A. & Obayelu, A. E. Assessing changes in the value of ecosystem services in response to land-use/land-cover dynamics in Nigeria. Science of the total Environment 636, 597–609 (2018).
Google Scholar
-
Hansen, M. C. & Loveland, T. R. A review of large area monitoring of land cover change using Landsat data. Remote sensing of Environment 122, 66–74 (2012).
Google Scholar
-
Desta, H. & Fetene, A. Land-use and land-cover change in Lake Ziway watershed of the Ethiopian Central Rift Valley Region and its environmental impacts. Land Use Policy 96, 104682 (2020).
Google Scholar
-
Winkler, K., Fuchs, R., Rounsevell, M. & Herold, M. Global land use changes are four times greater than previously estimated. Nature communications 12(1), 2501 (2021).
Google Scholar
-
Yang, J. & Huang, X. The 30 m annual land cover dataset and its dynamics in China from 1990 to 2019. Earth System Science Data 13(8), 3907–3925 (2021).
Google Scholar
-
Gómez, C., White, J. C. & Wulder, M. A. Optical remotely sensed time series data for land cover classification: A review. ISPRS Journal of photogrammetry and Remote Sensing 116, 55–72 (2016).
Google Scholar
-
Calderón-Loor, M., Hadjikakou, M. & Bryan, B. A. High-resolution wall-to-wall land-cover mapping and land change assessment for Australia from 1985 to 2015. Remote Sensing of Environment 252, 112148 (2021).
Google Scholar
-
Congalton, R. G., Gu, J., Yadav, K., Thenkabail, P. & Ozdogan, M. Global land cover mapping: A review and uncertainty analysis. Remote Sensing 6(12), 12070–12093 (2014).
Google Scholar
-
Naboureh, A., Bian, J., Lei, G. & Li, A. A review of land use/land cover change mapping in the China-Central Asia-West Asia economic corridor countries. Big Earth Data 5(2), 237–257 (2021).
Google Scholar
-
Hu, Z. et al. Temporal and spatial variations in the terrestrial water storage across Central Asia based on multiple satellite datasets and global hydrological models. Journal of Hydrology 596, 126013 (2021).
Google Scholar
-
Feizizadeh, B. et al. Scenario-based analysis of the impacts of lake drying on food production in the Lake Urmia Basin of Northern Iran. Scientific reports 12(1), 1–16 (2022).
Google Scholar
-
Huang, S. et al. Impacts of climate change and evapotranspiration on shrinkage of Aral Sea. Science of the Total Environment 845, 157203 (2022).
Google Scholar
-
Feizizadeh, B., Garajeh, M. K., Lakes, T. & Blaschke, T. A deep learning convolutional neural network algorithm for detecting saline flow sources and mapping the environmental impacts of the Urmia Lake drought in Iran. Catena 207, 105585 (2021).
Google Scholar
-
Li, Q. et al. Investigate the relationships between the Aral Sea shrinkage and the expansion of cropland and reservoir in its drainage basins between 2000 and 2020. International Journal of Digital Earth 14(6), 661–677 (2021).
Google Scholar
-
Gong, P. et al. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. International Journal of Remote Sensing 34(7), 2607–2654 (2013).
Google Scholar
-
Bartholome, E. & Belward, A. S. GLC2000: a new approach to global land cover mapping from Earth observation data. International Journal of Remote Sensing 26(9), 1959–1977 (2005).
Google Scholar
-
Friedl, M. A. et al. MODIS Collection 5 global land cover: Algorithm refinements and characterization of new datasets. Remote sensing of Environment 114(1), 168–182 (2010).
Google Scholar
-
Sun, B., Chen, X. & Zhou, Q. Uncertainty assessment of GlobeLand30 land cover data set over central Asia. The International Archives of Photogrammetry. Remote Sensing and Spatial Information Sciences 41, 1313 (2016).
-
Naboureh, A., Li, A., Bian, J. & Lei, G. National Scale Land Cover Classification Using the Semiautomatic High-Quality Reference Sample Generation (HRSG) Method and an Adaptive Supervised Classification Scheme. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 16, 1858–1870 (2023).
Google Scholar
-
Woodcock, C. E. et al. Free access to Landsat imagery. Science 320(5879), 1011–1011 (2008).
Google Scholar
-
Pekel, J.-F., Cottam, A., Gorelick, N. & Belward, A. S. High-resolution mapping of global surface water and its long-term changes. Nature 540, 418–422 (2016).
Google Scholar
-
Shafizadeh-Moghadam, H., Khazaei, M., Alavipanah, S. K. & Weng, Q. Google Earth Engine for large-scale land use and land cover mapping: An object-based classification approach using spectral, textural and topographical factors. GIScience & Remote Sensing 58(6), 914–928 (2021).
Google Scholar
-
Köppen, W. Versuch einer Klassifikation der Klimate, vorzugsweise nach ihren Beziehungen zur Pflanzenwelt.(Schluss). Geographische Zeitschrift 6(12), 657–679 (1900).
-
Zhu, Z. & Woodcock, C. E. Continuous change detection and classification of land cover using all available Landsat data. Remote sensing of Environment 144, 152–171 (2014).
Google Scholar
-
Fick, S. E. & Hijmans, R. J. WorldClim 2: new 1-km spatial resolution climate surfaces for global land areas. International journal of climatology 37(12), 4302–4315 (2017).
Google Scholar
-
Chen, J. et al. Global land cover mapping at 30 m resolution: A POK-based operational approach. ISPRS Journal of Photogrammetry and Remote Sensing 103, 7–27 (2015).
Google Scholar
-
Zhang, X. et al. GWL_FCS30: global 30 m wetland map with fine classification system using multi-sourced and time-series remote sensing imagery in 2020. Earth System Science Data 15, 265–293 (2022).
Google Scholar
-
Gong, P. et al. Annual maps of global artificial impervious area (GAIA) between 1985 and 2018. Remote Sensing of Environment 236, 111510 (2020).
Google Scholar
-
Remelgado, R. et al. A crop type dataset for consistent land cover classification in Central Asia. Scientific data 7(1), 250 (2020).
Google Scholar
-
Ma, L. et al. A review of supervised object-based land-cover image classification. ISPRS Journal of Photogrammetry and Remote Sensing 130, 277–293 (2017).
Google Scholar
-
Belgiu, M. & Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS journal of photogrammetry and remote sensing 114, 24–31 (2016).
Google Scholar
-
Ebrahimy, H., Naboureh, A., Feizizadeh, B., Aryal, J. & Ghorbanzadeh, O. Integration of Sentinel-1 and Sentinel-2 Data with the G-SMOTE Technique for Boosting Land Cover Classification Accuracy. Applied Sciences 11(21), 10309 (2021).
Google Scholar
-
Brown, C. F. et al. Dynamic World, Near real-time global 10 m land use land cover mapping. Scientific Data 9(1), 251 (2022).
Google Scholar
-
Naboureh, A., Bian, J., Li, A., Lei, G. & Nan, X. Land cover dataset of the China Central-Asia West-Asia Economic Corridor from 1993 to 2018. National Tibetan Plateau Data Center. https://doi.org/10.11888/Terre.tpdc.300482 (2023).
-
Naboureh, A. et al. Assessing the effects of irrigated agricultural expansions on Lake Urmia using multi-decadal Landsat imagery and a sample migration technique within Google Earth Engine. International Journal of Applied Earth Observation and Geoinformation 105, 102607 (2021).
Google Scholar
-
Rouse, J. W. Jr, Haas, R. H., Deering, D. W., Schell, J. A. & Harlan, J. C. Monitoring the vernal advancement and retrogradation (green wave effect) of natural vegetation. NASA E75, 10354 (1974).
-
Diek, S., Fornallaz, F., Schaepman, M. & de Jong, R. Barest pixel composite for agricultural areas using landsat time series. Remote Sensing 9, 1245 (2017).
Google Scholar
-
Marsett, R. C. et al. Remote sensing for grassland management in the arid southwest. Rangeland Ecology & Management 59(5), 530–540 (2006).
Google Scholar
-
Zha, Y., Gao, J. & Ni, S. Use of normalized difference built-up index in automatically mapping urban areas from TM imagery. International journal of remote sensing 24(3), 583–594 (2003).
Google Scholar
-
Qi, J., Chehbouni, A., Huete, A. R., Kerr, Y. H. & Sorooshian, S. A modified soil adjusted vegetation index. Remote sensing of environment 48(2), 119–126 (1994).
Google Scholar
-
Roy, D. P., Boschetti, L. & Trigg, S. N. Remote sensing of fire severity: assessing the performance of the normalized burn ratio. IEEE Geoscience and remote sensing letters 3(1), 112–116 (2006).
Google Scholar
-
Carlson, T. N. & Ripley, D. A. On the relation between NDVI, fractional vegetation cover, and leaf area index. Remote sensing of Environment 62(3), 241–252 (1997).
Google Scholar
Acknowledgements
This research was jointly supported by the National Key Research and Development Program of China (2020YFA0608702), the National Natural Science Foundation project of China (42090015 and 41801370), the Strategic Priority Research Program of Chinese Academy of Sciences (XDA19030303), and the Youth Innovation Promotion Association Chinese Academy of Sciences (2019365).
Author information
Authors and Affiliations
Contributions
Amin Naboureh conceptualized the work, wrote the code, and generated the database. Ainong Li supervised the project. Jinhu Bian, Guangbin Lei, and Xi Nan provided formal analysis and validation. All authors contributed in writing the manuscript and analysed the dataset.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Reprints and Permissions
About this article
Cite this article
Naboureh, A., Li, A., Bian, J. et al. Land cover dataset of the China Central-Asia West-Asia Economic Corridor from 1993 to 2018.
Sci Data 10, 728 (2023). https://doi.org/10.1038/s41597-023-02623-z
-
Received: 23 May 2023
-
Accepted: 21 September 2023
-
Published: 20 October 2023
-
DOI: https://doi.org/10.1038/s41597-023-02623-z