Abstract
In the United States, much has been learned about the determinants of longevity from survey data and aggregated tabulations. However, the lack of large-scale, individual-level administrative mortality records has proven to be a barrier to further progress. We introduce the CenSoc datasets, which link the complete-count 1940 U.S. Census to Social Security mortality records. These datasets—CenSoc-DMF (N = 4.7 million) and CenSoc-Numident (N = 7.0 million)—primarily cover deaths among individuals aged 65 and older. The size and richness of CenSoc allows investigators to make new discoveries into geographic, racial, and class-based disparities in old-age mortality in the United States. This article gives an overview of the technical steps taken to construct these datasets, validates them using external aggregate mortality data, and discusses best practices for working with these datasets. The CenSoc datasets are publicly available, enabling new avenues of research into the determinants of mortality disparities in the United States.
Background & Summary
The CenSoc datasets—so termed because they link the full-count 1940 Census (“Cen”) with Social Security Administration mortality records (“Soc”)—represent the first large-scale, nationally representative, publicly available data resource for researchers studying mortality. We constructed two datasets, the CenSoc-DMF (N = 4.7 million) and CenSoc-Numident (N = 7.0 million), both primarily composed of deaths over the age of 65. The scale and detail of CenSoc data allow researchers to make new discoveries in areas such as (i) mortality disparities by education, national origin, and race; (ii) early life conditions and later-life mortality; (iii) geographic variation and the neighborhood determinants of mortality; and (iv) natural experiments from local policies and chance events such as natural disasters. These research areas are of growing importance in understanding increases in disparities in life expectancy in the United States. Here, we describe how the CenSoc datasets were constructed, validate these datasets by benchmarking them against gold-standard aggregated mortality statistics, and discuss best practices for working with these datasets.
We are far from a complete understanding of the social determinants of longevity. Despite the longstanding interest in racial and class-based inequalities in health and mortality in the United States1,2, research is often limited by the lack of individual-level data3,4. Most research into the general dimensions of mortality disparities using individual-level data have relied on survey data, with sample sizes that preclude the analysis of smaller population subgroups such as the “oldest old” or minority populations. In the absence of comprehensive population-level registry data, researchers are increasingly turning to linked administrative datasets to answer some of the most pressing questions in social science research3,5,6,7,8. Yet many of these new linked administrative datasets—especially for mortality research—are only available in restricted contexts, limiting opportunities for replicating and extending analyses conducted with the data.
Fortunately, the data landscape for mortality researchers is improving. Recently, the U.S. Census Bureau has made available an internal, restricted-access version of the Numident, which has been linked to a series of economic, survey, and administrative data including the 1940, 2000, and 2010 Censuses9. These restricted data can be accessed in Federal Statistical Research Data Centers (FSRDC) and provide nearly complete mortality coverage from 1975 to the present. Another major data infrastructure project is the publicly available LIFE-M project, which links intergenerational census records to mortality records10. The LIFE-M linkages are based on a random sample of birth certificates in Ohio and North Carolina and track four generations of individuals longitudinally over the life course. These projects all represent important advances in data infrastructure for mortality researchers.
The comparative advantages of CenSoc are twofold. First, the CenSoc datasets are publicly available for unrestricted download, without the need for prior approval. This ensures that investigations with CenSoc data are reproducible and extendable. Second, the massive, nationally-representative sample allows researchers to conduct high-resolution mortality research, investigating disparities for smaller population subgroups and fine geographic areas. Early versions of CenSoc datasets have been used to make new findings concerning the long-run longevity benefits of education11,12, the impact of environmental disasters on mortality13,14, social insurance programs’ influence on later-life mortality15, and the relationship between homeownership and longevity16. These projects represent early applications of CenSoc data, and many opportunities remain.
Methods
To construct the CenSoc datasets, we link the 1940 Census to two distinct sources of mortality data: the public Social Security Numident File (“Numident”) and the Social Security Death Master File (“DMF”). As there is no shared unique identifier between the 1940 Census and mortality records (e.g., a Social Security number), we use nominal record linkage algorithms to link the census and mortality records at the individual level17,18. We create two separate linked datasets—the CenSoc-DMF and the CenSoc-Numident—because the DMF and Numident have different fields available for record linkage and different mortality coverage windows. We describe the input datasets and our record linkage strategy below.
Input datasets
1940 census
The 1940 Census, conducted on April 1st, 1940, collected information on over 132 million Americans living in 44 million households. The 1940 Census form included 34 population questions and 31 housing questions and was the first U.S. census to include questions on wage and salary income, educational attainment, and detailed employment status. In addition, it collected information on exact street address, place of birth, citizenship, homeowner status, occupation, and more. The 1940 Census was also the first U.S. Census to leverage modern sampling techniques: every 20 person was asked 16 additional questions on topics such as their mother’s and father’s birthplace, veteran status, holder of a Social Security number, number of times married, age at first marriage, and number of children ever born. The 1940 Census was taken after the worst of the Great Depression and before the large war-time mobilization that soon followed, in a “business as usual” setting.
The 1940 Census records were made publicly available following the 72-year waiting period mandated by law. Following their public release, the Census records were digitized by the American genealogy company Ancestry and made available to the research community by IPUMS-USA8,19. Per an agreement with Ancestry, the public version of the 1940 Census from IPUMS-USA omits names and street addresses. A restricted version of the 1940 Census is available for researchers to access in restricted data enclaves, which includes names and street addresses. We use this restricted version of the 1940 Census to construct the CenSoc datasets, which we then publish using the public individual identifiers in the IPUMS 1940 Census public file.
Social security death master file
Our first set of death records comes from the Social Security Death Master File (DMF). The DMF has been used for both academic research20 and identity fraud prevention by financial services companies and government agencies. The DMF contains over 83 million death records, with nearly-complete coverage (95%+) from 1975–2005. Outside of this window, death coverage drops dramatically21,22. Each DMF death record contains full first and last name, exact date of birth (d/m/y), and exact date of death (d/m/y). The DMF does not contain information on gender or place of birth.
NARA social security numident file
Our second set of mortality records comes from the Social Security Numident File. The Numident is the backbone of the Social Security Administration’s record keeping system. For each person with a Social Security Number, the Numident tracks date of birth, date of death (if applicable), claims status, and other background information such as birthplace, race, sex, and parents’ first and last names. A subset of the Numident records was transferred to the National Archives and Record Administration (NARA) for public release. The public Numident contains nearly complete death coverage for Social Security Number holders between 1988 and 2005 and includes two additional record linkage fields not available in the DMF: place of birth and information on parents’ last names. Parents’ last names are especially valuable for record linkage because they enable researchers to determine a woman’s maiden name.
We cleaned and harmonized the public Numident application, claims, and death records into a single harmonized file: the Berkeley Unified Numident Mortality Database (BUNMD)23. This publicly-available file includes nearly 50 million death records but lacks the covariates available in the 1940 Census.
Record linkage
To establish matches between the 1940 Census and mortality records, we use a deterministic record linkage algorithm, the “conservative” version of the ABE exact record linkage algorithm24,25,26. This linking strategy requires an exact match on standardized first name, last name, and place of birth (for Numident only). Priority is given to exact matches on age in 1940, with additional flexibility of up to ±2 years allowed. We use this conservative approach to establishing a match to prioritize minimizing the number of false matches over maximizing the total match rate17. As new matching methods emerge, we can create and release updated versions of these linkages, minimizing linkage errors with potential implications for the inferences drawn from these data18.
Matching methods for women
Nominal record linkage is difficult for women because of changes from maiden to married names. In our setting, if a woman marries and changes her last name after the 1940 Census, her census and death records will have different last names, making it impossible to successfully establish a match. While we are not able to link women between the 1940 Census and the DMF, we are able to link women between the 1940 Census and the Numident using information on the father’s last name available in the Numident record. Specifically, we first identify marital status using information in the 1940 Census. For ever-married women, we link using last name in both the 1940 Census and the Numident, exactly the same as we do for men. For never-married women, we use their father’s last name in the Numident as a proxy for the last name they reported in the 1940 Census. (We note that this method cannot match women who re-married and changed their name again after 1940.)
Statistical weights
To account for differences in inclusion probabilities by period, age, and demographic characteristics, we generate post-stratification weights using population totals from the Multiple Cause-of-Death (MCOD) mortality data from the National Vital Statistics System of the National Center for Health Statistics (NCHS)27. The MCOD datasets compile individual-level data from death certificates for all deaths that occur within the United States. The primary purpose of weights is to adjust for slightly worse coverage of younger ages of death within birth cohorts.
For people who were born in the contiguous United States (including the District of Columbia), died aged 65–100, and died during the years of 1988–2005 (CenSoc-Numident) or 1979–2005 (CenSoc-DMF), we weight up directly to population totals from NCHS data. For each dataset, individuals are split into cells cross-classified by year of death (y), age at death (a), sex (s), race (r), and birth state (b). We assign each person in a given cell a weight equal to the ratio of deaths in the NCHS data to deaths in the CenSoc data:
To construct the weights, we use three race categories: Black, White, and Other. We are not able to use more detailed race categories due to comparability issues in race categories between the 1940 Census and the NCHS death certificates. We do not weight on Hispanic origin or ethnicity, as it is not directly available in the 1940 Census and was reported inconsistently across time and place in the NCHS death certificates.
The universe of deaths for CenSoc and NCHS data differ slightly. CenSoc data captures individuals with Social Security numbers (SSNs), including people with SSNs dying abroad. In contrast, NCHS data may include non-residents and non-SSN holders that died in the U.S. The presence of non-SSN holders in NCHS data, in addition to immigrants who entered the country after the 1940 census, are mainly problematic for weighting decedents born abroad. We assign immigrants alternative weights. We are not able to assign weights to those born in America and dying abroad because we cannot identify deaths that occur abroad. However, such deaths are small in number, ranging from several thousand to tens of thousands9,28. While the age and birthplace compositions of persons dying abroad are largely unknown, the absence of such deaths in NCHS data may slightly deflate weights among age 65+ American-born SSN holders.
Non-standard weights
A portion of CenSoc data cannot be directly weighted using the weighting strategy described above. We address the following types of problematic records as follows:
-
Deaths in the years 1975–1978: Birth state of decedents is not available in MCOD data from 1975–1978. For years prior to 1979, we assign the same weight for age/race/birthplace strata as in 1979.
-
Decedents born abroad, in current U.S. territories, Alaska, and Hawaii: Any person born outside the 48 contiguous United States and the District of Columbia is only observable in CenSoc if they moved to the contiguous U.S. before census day in 1940. NCHS totals for these groups are inappropriate to use for weighting, as immigrants who entered the country after 1940 are included, as well as all Alaskans and Hawaiians. Instead, we assign records the mean weight of U.S.-born decedents of the same year, age, race, and sex.
-
Records not weightable due to other data issues: A very small number of records cannot be weighted directly due to issues like missing birthplace or because they belong to a stratum not present in NCHS population data. We first attempt to assign these records the mean weight of U.S-born decedents of the same age, year, sex, and race. If this fails, records are given a weight of 1 (necessary for less than 600 records in each data set).
Weighting adjustments
The unadjusted weighted CenSoc deaths to American-born decedents from 1979–2005 total only 99.5% of NCHS death tallies, due to presence of age/year/sex/race/birthplace cells extant in NCHS data but not captured by CenSoc. To address bias introduced by empty cells, we utilize raking ratio estimation29, as implemented with the R package Survey30, to calibrate weighted marginal totals to population marginal totals by year, age, race, sex, and birthplace.
The raw post-stratification weights also contain extreme weights. We trim weights to a minimum of 1 and a maximum of 5 times the mean unadjusted weights to reduce the potential impact of extremely high weights on analyses. Less than 1% of raw weights fell above the maximum threshold. Weights for the years 1975–1978 and the foreign-born are trimmed but not otherwise calibrated or adjusted due to absence of useable population totals. For American-born decedents in the years 1979–2005, records are iteratively raked and trimmed until weights are both calibrated to population marginal totals and fall within an acceptable range.
Data Records
CenSoc data download
The CenSoc datasets and their accompanying documentation are publicly available for download from the Harvard Dataverse31,32. Researchers must sign an agreement to properly cite and not redistribute the data. Table 1 provides an overview of the key features of the CenSoc-DMF and CenSoc-Numident datasets.
Censoc-DMF
The CenSoc-DMF file is comprised of approximately 4.7 million person-level records and 7 variables31. The histid variable uniquely identifies each record in the dataset. The other variables report statistical weights, dates of birth, and dates of death (see Table 2). The CenSoc-DMF file only includes men, as surname changes at the time of marriage preclude accurate linkage of women. To access the 50+ variables available in the 1940 Census, such as census race, education, wage and salary income, small area geographic identifiers, and occupation, researchers must link the CenSoc-DMF onto the publicly-available IPUMS 1940 Census on the unique identifier histid.
CenSoc-numident
The CenSoc-Numident file is comprised of approximately 7.0 million records and 18 variables32. The histid variable is a unique identifier that is also available in the public 1940 Census records. The other variables report a statistical weight, date of birth, date of death, birthplace, race, and ZIP code of residence at time of death (see Table 3). The CenSoc-Numident file contains both men and women. To access the 50+ variables available in the 1940 Census (e.g., census race, education, wage income, small area identifiers, and occupation), investigators must link the CenSoc-Numident onto the publicly-available IPUMS 1940 Census on the unique identifier histid.
Technical Validation
Validation of mortality rates
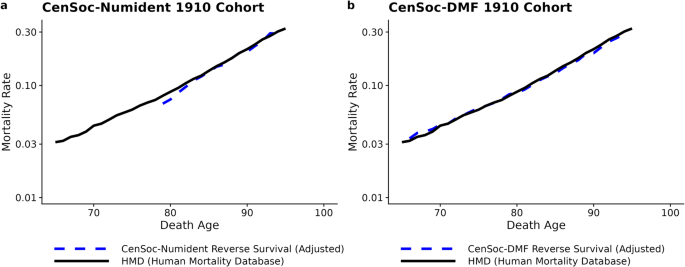
As a validation exercise, we estimate the cohort age-specific mortality rates from the CenSoc datasets and benchmark them against the Human Mortality Database33, the world’s leading scientific data resource on aggregate mortality statistics in developed countries. To estimate the age-specific cohort mortality rate, we use the extinct cohort method34,35,36. Specifically, within a given cohort, we calculate the total number of survivors at a given age by summing up all the deaths which occurred above that age. For cohorts that are not extinct by the end of our mortality observation window, such as the cohort of 1910, we estimate the additional number of cohort deaths occurring after our mortality observation window ends using the Human Mortality Database cohort exposure-to-risk data33. We then calculate the age-specific mortality rates from age-specific ratios of deaths to survivors.
Figure 1 shows the estimated age-specific mortality rate benchmarked against the age-specific mortality rate from the Human Mortality Database (HMD) for the cohort of 1910. The estimated age-specific mortality rates align closely for both the CenSoc-DMF and the CenSoc-Numident, demonstrating the aggregate mortality rates from the CenSoc datasets closely replicate gold-standard age-specific mortality estimates. We would not expect identical mortality rates from the two data sources as the CenSoc matches do not include post-1940 immigrants, while the HMD is influenced by migration effects after 1940.

Estimated age-specific mortality rates for the cohort of 1910 from the CenSoc-Numident (panel a) and CenSoc-DMF (panel b) benchmarked against the cohort age-specific mortality rates from the Human Mortality Database (HMD). The cohort age-specific mortality rates from the CenSoc datasets were calculated using the extinct cohort method. Note: Figures are given in the log-scale.
Validation of mortality estimates
The CenSoc datasets allow researchers to investigate the relationship between early life sociodemographic characteristics and later-life longevity11,13,16,37. To validate estimates of the association between covariates and longevity using CenSoc data, we present an updated example from Goldstein et al.38 on the association between education and longevity. Table 4 compares the estimated educational gradient in longevity from the CenSoc datasets to external estimates from three other studies relying on different sources of mortality data12,39,40. The estimated education gradient in longevity from CenSoc-DMF and CenSoc-Numident align closely with the external educational gradient estimates from the other three other studies. This agreement demonstrates that the CenSoc datasets can produce reliable estimates of the association between covariates and longevity.
Validation of mortality coverage
As a validation exercise, we benchmark the number of deaths captured in the original Numident and DMF mortality files against the Human Mortality Database (HMD) totals33. The mortality coverage for deaths to individuals 65+ is over 95% in the Numident (Fig. 2a) between 1988–2005 and over 95% in the DMF (Fig. 2b) between 1975–2005. Outside these windows, mortality coverage is very low. We restrict our universe of potential matches for the CenSoc-DMF and CenSoc-Numident datasets to deaths occurring in the high mortality coverage window.

Mortality coverage of the unweighted Numident (panel a) and unweighted DMF (panel b) datasets. The gray vertical dashed lines bound the high mortality coverage window for each respective dataset. The weighted CenSoc-DMF and CenSoc-DMF counts (not shown) are generally slightly lower than total population (HMD) deaths, as the HMD figures include post-1940 immigration.
We match 22% of Numident records and 17% of DMF records to the 1940 Census. This match rate is comparable to other efforts linking historical data26. We note that our primary focus is ensuring the accuracy and representativeness of the matches rather than maximizing the overall number of matches. Weights can account for differential mortality coverage over time.

Illustration of merging the CenSoc-DMF to an IPUMS 1940 Census data extract on HISTID, a shared unique identifier in both files. Columns shaded light grey represent information only in the CenSoc-DMF file; columns shaded dark grey represent information only available in the 1940 Census.
Validation of matching
Representativeness of matches
The representativeness of our CenSoc matches can be assessed relative to those who died in the coverage period and/or those alive in 1940. Our weighting strategy assures representativeness with respect to deaths. Even with a representative set of deaths, our nominal record linkage procedure will introduce some selection into our final matches. We can compare the characteristics of individuals enumerated in the 1940 Census to the subset of individuals successfully matched in the CenSoc datasets. The representativeness of the CenSoc matches for the pooled birth cohorts of 1900–1920 is presented in Tables 5–7. The CenSoc-DMF and CenSoc-Numident datasets reflect the general population but slightly overrepresent higher socioeconomic status individuals. For instance, the percentage of men in the CenSoc-DMF who did not complete high school (62.5%) is slightly lower than the general population (65.3%). Black people are underrepresented in both datasets, comprising 9.6% of the general male population but only 3.9% of the CenSoc-DMF and 5.0% of men in the CenSoc-Numident. Weights help correct for some of this underrepresentation: 8.9% of the men in weighted CenSoc-DMF and 7.8% of the men in the weighted CenSoc-Numident are Black, aligning more closely to the 9.6% of men who are Black in the 1940 Census. Additionally, despite the lower match rate, the sociodemographic characteristics of matched Black individuals closely align with those of the general Black population23.
The representativeness of the matches has implications for inference. If the under or overrepresented population subgroups differ on the outcome of interest, this may lead to biased estimates of population-level parameters18. To address this, researchers can conduct stratified analyses (e.g., fit separate models for Black and White subgroups). However, the errors introduced by sample non-representativeness are generally modest compared to errors introduced by false matches17,18.
Validation using middle initials
To assess the accuracy of matches in the absence of ground-truth data, we investigate the agreement between the middle initials reported in the Census and the mortality record. As middle initial was not used as a matching field, we interpret the rate of disagreement on middle initials as an upper bound for the false match rate. Disagreements on middle initials may reflect an actual false match or a correct match where middle initials disagree due to reporting errors, transcription errors, or digitization errors. We use middle initials rather than full middle names because full middle names are rarely available in both Census and mortality records. We restrict our analysis to men to avoid complications with middle name changes at the time of marriage for women.
In the CenSoc-Numident, middle initials are available for 78% of Numident records, 30% of 1940 Census records, and 27% of records in both datasets. Of the 27% of records that have a middle initial in both datasets, middle initial agrees in 87% of the records. Middle initials are available for 43% of records in the DMF, 30% of records in the 1940 Census, and 15% of records in both datasets. Middle initials agree in 85% of matches in the CenSoc-DMF. Given the high rate of transcription errors in the 1940 Census26, the middle-initial agreement rate of 85% suggests an even higher level of correct matches.
Usage Notes
Linking censoc files with the ipums 1940 census
Researchers can download the public CenSoc files and link them with the complete-count 1940 Census on the unique identifier histid, which is available in both datasets (Fig. 3). Researchers can freely download a copy of the 1940 Census from IPUMS-USA19. Custom data extracts of the 1940 Census can be obtained by creating an account at https://usa.ipums.org/usa/https://usa.ipums.org/usa/ and selecting variables of interest (including histid) to download. Census data extracts may take several hours to be generated and take additional time to download. Researchers can alternatively access a restricted version of the complete-count 1940 Census at one of the IPUMS-approved secure data enclaves. The secure version of the 1940 Census includes first and last names and street-level addresses in addition to all the covariates in the public 1940 Census. In addition, researchers can download a prelinked “demo” versions of the CenSoc files, containing a 1% sample of the complete CenSoc datasets with 20 mortality covariates from the 1940 Census41.
Mortality estimation
One technical limitation of the CenSoc datasets is that they include records for individuals who have died, without information on survivors. In addition, the datasets only include deaths for a left and right (“doubly”) truncated window. This situation of having “deaths without denominators” precludes the calculation of occurrence-exposure mortality rates and the use of the conventional tools of individual-level survival analysis21. In the presence of double-truncation, methods such as Cox-Proportional hazards methods or linear regression on age of death will result in attenuated estimates of regression coefficient38.
If researchers use conventional regression methods, they should keep in mind first that their coefficients will be biased toward zero (attenuated). Second, it is important that researchers include fixed effects for year of birth. We recommend fitting regressions of the form:
where β0 is a general intercept, γt is the intercept for individuals born in year t, and β is the effect of a covariate Zi on age of death. The birth year fixed effects are crucial to include because people born earlier will be observed dying at older ages.
We have also developed open-source software in the R language to estimate unbiased effects on mortality rates subject to double truncation of death counts38. The package Gompertztrunc is available to download at https://cran.r-project.org/web/packages/gompertztrunc/index.htmlCRAN. This approach assumes mortality follows a parametric Gompertz distribution and uses maximum likelihood estimation techniques to estimate mortality differentials. Specifically, we assume mortality follows a parametric Gompertz hazard model where the likelihood associated with a set of observed ages of death xi with parameters θ (e.g., the intercept and slope of the log-Gompertz curve, which may themselves be functions of covariates) is given by the product of the normalized densities, with truncation on the right at age ({x}_{i}^{r}) and on the left at age ({x}_{i}^{l}):
where f is the density and F is the cumulative distribution.
For example, a proportional hazards model for the effect of covariates on mortality for individual i aged x with covariates Zi assuming baseline Gompertz hazards is given by:
where α0 and b0 are baseline Gompertz parameters. In this case, the observed data would contain for each person values xi for the age of death, Zi for covariates (e.g., years of education, place of birth), and the right and left truncation ages ({x}_{i}^{r}) and ({x}_{i}^{l}) for each cohort. The model estimates would be the parameter values ({widehat{a}}_{0},{widehat{b}}_{0}) and (widehat{beta }). For a more comprehensive discussion of this method, please see Goldstein et al.38.
When possible, we recommend researchers work with this parametric Gompertz approach designed for estimating mortality disparities in the presence of double truncation. If researchers analyze CenSoc data using conventional methods such as OLS regression on age of death, they must clearly state that the estimated regression coefficients are attenuated by the double truncation.
Research outside high coverage time periods
To date, most efforts involving weighting and mortality analysis have been developed for the high-coverage period over age 65. This roughly corresponds to birth cohorts of 1900–1925 for CenSoc-DMF and birth cohorts of 1910–1925 for CenSoc-Numident. Although it is possible to work with birth cohorts outside of this window, researchers should proceed with caution, spending extra time and effort on weighting and mortality estimation methods.
Linkage to other datasets
The CenSoc datasets can also be linked onto other census or administrative records. For instance, researchers can take advantage of recent advances in census linkage infrastructure. Both the IPUMS Multi-Generational Longitudinal Panel Project (IPUMS-MLP)19 and the Census Linkage Project42 have publicly released crosswalks linking the complete-count decennial censuses from 1870–1940. Using these resources, researchers can track individuals in CenSoc longitudinally throughout their life course. In addition, researchers can also link CenSoc onto other datasets using the matching fields available in the CenSoc datasets. We have recently publicly released the CenSoc Army Enlistment Records, which link the CenSoc datasets to the World War II Army Records (N = 9 million) to obtain new covariates such as height, weight, and army rank. We also plan to link both the DMF and Numident mortality records onto the 1950 Census following its release from IPUMS.
Code availability
The original scripts to clean, process, and match the original 1940 Census and mortality records were written in the R programming language. They are available at https://github.com/caseybreen/censocdevgithub.com/caseybreen/censocdev. The code to reproduce all figures and tables in this paper is available from the Open Science Framework43.
References
-
Schwandt, H. et al. Inequality in mortality between Black and White Americans by age, place, and cause and in comparison to Europe, 1990 to 2018. Proceedings of the National Academy of Sciences 118, e2104684118, https://doi.org/10.1073/pnas.2104684118 (2021).
Google Scholar
-
Elo, I. T. Social Class Differentials in Health and Mortality: Patterns and Explanations in Comparative Perspective. Annual Review of Sociology 35, 553–572, https://doi.org/10.1146/annurev-soc-070308-115929 (2009). 27800091.
Google Scholar
-
Card, D., Dobkin, C. & Maestas, N. The Impact of Nearly Universal Insurance Coverage on Health Care Utilization: Evidence from Medicare. American Economic Review 98, 2242–2258, https://doi.org/10.1257/aer.98.5.2242 (2008).
Google Scholar
-
Song, X. & Coleman, T. S. Using Administrative Big Data to Solve Problems in Social Science and Policy Research. University of Pennsylvania Population Center Working Paper (PSC/PARC), 2020-58. https://repository.upenn.edu/psc_publications/58 (2020).
-
Chetty, R. et al. The Association Between Income and Life Expectancy in the United States, 2001–2014. JAMA 315, 1750, https://doi.org/10.1001/jama.2016.4226 (2016).
Google Scholar
-
Card, D. E., Chetty, R., Feldstein, M. S. & Saez, E. Expanding Access to Administrative Data for Research in the United States. American Economic Association, Ten Years and Beyond: Economists Answer NSF’s Call for Long-Term Research Agendas. https://doi.org/10.2139/ssrn.1888586 (2010).
-
Meyer, B. D. & Mittag, N. Using Linked Survey and Administrative Data to Better Measure Income: Implications for Poverty, Program Effectiveness, and Holes in the Safety Net. American Economic Journal: Applied Economics 11, 176–204, https://doi.org/10.1257/app.20170478 (2019).
Google Scholar
-
Ruggles, S. Big Microdata for Population Research. Demography 51, 287–297, https://doi.org/10.1007/s13524-013-0240-2 (2014).
Google Scholar
-
Finlay, K. & Genadek, K. R. Measuring All-Cause Mortality With the Census Numident File. American Journal of Public Health 111, S141–S148, https://doi.org/10.2105/AJPH.2021.306217 (2021).
Google Scholar
-
Bailey, M. J. et al. LIFE-M: The Longitudinal, Intergenerational Family Electronic Micro-Database https://doi.org/10.3886/E155186V5 (2022).
Google Scholar
-
Fletcher, J. & Noghanibehambari, H. The Effects of Education on Mortality: Evidence Using College Expansions. Tech. Rep. w29423, https://doi.org/10.3386/w29423 National Bureau of Economic Research, Cambridge, MA (2021).
-
Lleras-Muney, A., Price, J. & Yue, D. The Association Between Educational Attainment and Longevity using Individual Level Data from the 1940 Census. NBER Working Paper Serie. https://doi.org/10.3386/w27514 (2020).
Google Scholar
-
Atherwood, S. Does a prolonged hardship reduce life span? Examining the longevity of young men who lived through the 1930s Great Plains drought. Population and Environment 43, 530–552 (2022).
Google Scholar
-
Noghanibehambari, H. In utero exposure to natural disasters and later-life mortality: Evidence from earthquakes in the early twentieth century. Social Science & Medicine 307, 115189, https://doi.org/10.1016/j.socscimed.2022.115189 (2022).
Google Scholar
-
Noghanibehambari, H. & Engelman, M. Social insurance programs and later-life mortality: Evidence from new deal relief spending. Journal of Health Economics 86, 102690, https://doi.org/10.1016/j.jhealeco.2022.102690 (2022).
Google Scholar
-
Breen, C. F. The Longevity Benefits of Homeownership https://doi.org/10.31235/osf.io/7ya3f (2023).
Google Scholar
-
Ruggles, S., Fitch, C. A. & Roberts, E. Historical Census Record Linkage. Annual Review of Sociology 44, 19–37, https://doi.org/10.1146/annurev-soc-073117-041447 (2018).
Google Scholar
-
Bailey, M., Cole, C., Henderson, M. & Massey, C. How Well Do Automated Linking Methods Perform? Lessons from U.S. Historical Data. Journal of economic literature 58, 997–1044, https://doi.org/10.1257/jel.20191526 (2020).
Google Scholar
-
Ruggles, S. et al. IPUMS USA: Version 10.0 [dataset]. Minneapolis, MN: IPUMS. https://doi.org/10.18128/D010.V10.0 (2020).
Google Scholar
-
Schisterman, E. F. & Whitcomb, B. W. Use of the Social Security Administration Death Master File for ascertainment of mortality status. Population Health Metrics 2, 2, https://doi.org/10.1186/1478-7954-2-2 (2004).
Google Scholar
-
Alexander, M. Deaths without denominators: Using a matched dataset to study mortality patterns in the United States. Preprint, SocArXiv. https://doi.org/10.31235/osf.io/q79ye (2018).
-
Hill, M. E. The Social Security Administration’s Death Master File: The Completeness of Death Reporting at Older Ages. Social Security Bulletin 64 (2001).
-
Breen, C. & Osborne, M. An Assessment of CenSoc Match Quality. Preprint, SocArXiv. https://doi.org/10.31235/osf.io/bj5md (2022).
-
Abramitzky, R., Boustan, L. P. & Eriksson, K. Europe’s Tired, Poor, Huddled Masses: Self-Selection and Economic Outcomes in the Age of Mass Migration. American Economic Review 102, 1832–1856, https://doi.org/10.1257/aer.102.5.1832 (2012).
Google Scholar
-
Abramitzky, R., Boustan, L. P. & Eriksson, K. A Nation of Immigrants: Assimilation and Economic Outcomes in the Age of Mass Migration. Journal of Political Economy 122, 467–506, https://doi.org/10.1086/675805 (2014).
Google Scholar
-
Abramitzky, R., Boustan, L., Eriksson, K., Feigenbaum, J. & Pérez, S. Automated Linking of Historical Data. Journal of Economic Literature 59, 865–918 (2021).
Google Scholar
-
National Center for Health Statistics. Multiple Cause-of-Death Files (1975–2005), as compiled from data provided by the 57 vital statistics jurisdictions through the Vital Statistics Cooperative Program.
-
Baker, T. D., Hargarten, S. W. & Guptill, K. S. The uncounted dead–American civilians dying overseas. Public Health Reports (Washington, D.C.: 1974) 107, 155–159 (1992).
Google Scholar
-
Kalton, G. Compensating for missing survey data (1983).
-
Lumley, T. Survey: Analysis of complex survey samples (2023).
-
Goldstein, JR. et al. CenSoc-DMF, Harvard Dataverse, https://doi.org/10.7910/DVN/QGKF9Y (2023).
-
Goldstein, JR. et al. CenSoc-Numident, Harvard Dataverse, https://doi.org/10.7910/DVN/I0TLPI (2023).
-
HMD. Human Mortality Database. University of California, Berkeley (USA), and Max Planck Institute for Demographic Research (Germany) (2021).
-
Vincent, P. La mortalité des vieillards. Population 6, 181–204, https://doi.org/10.2307/1524149 (1951).
Google Scholar
-
Depoid, F. La mortalité des grands vieillards. Population 28, 755–792, https://doi.org/10.2307/1531256 (1973).
Google Scholar
-
Rau, R., Muszyńska, M. & Eilers, P. Minor gradient in mortality by education at the highest ages: An application of the Extinct-Cohort method. Demographic Research 29, 507–520, https://doi.org/10.4054/DemRes.2013.29.19 (2013).
Google Scholar
-
Noghanibehambari, H. & Fletcher, J. Dust to Feed, Dust to Grey: The Effect of In-Utero Exposure to the Dust Bowl on Old-Age Longevity, https://doi.org/10.3386/w30531. 30531 (2022).
-
Goldstein, J. R., Osborne, M., Breen, C. F. & Atherwood, S. Mortality Modeling of Partially Observed Cohorts Using Administrative Death Records. Soc Arxiv. 33 (2023).
-
Halpern-Manners, A., Helgertz, J., Warren, J. R. & Roberts, E. The Effects of Education on Mortality: Evidence From Linked U.S. Census and Administrative Mortality Data. Demography 57, 1513–1541, https://doi.org/10.1007/s13524-020-00892-6 (2020).
Google Scholar
-
Rogers, R. G., Everett, B. G., Zajacova, A. & Hummer, R. A. Educational Degrees and Adult Mortality Risk in the United States. Biodemography and Social Biology 56, 80–99, https://doi.org/10.1080/19485561003727372 (2010).
Google Scholar
-
Goldstein, J. et al. CenSoc Demo Files. Harvard Dataverse https://doi.org/10.7910/DVN/QVDPM9 (2023).
-
Abramitzky, R., Boustan, L., Eriksson, K., Pérez, S. & Rashid, M. Census Linking Project: Version 1.0 (2020).
-
Breen, C. F., Osborne, M. & Goldstein, J. R. Replication Code, CenSoc: Linked Public Administrative Mortality Records for Individual-level Mortality Research Open Science Framework https://doi.org/10.17605/OSF.IO/8R349 (2023).
Acknowledgements
The authors acknowledge the funding of NIH grants R01AG058940 and R01AG076830 and the University of California Berkeley Center on the Economics and Demography of Aging (National Institute of Aging 5P30AG012839).
Author information
Authors and Affiliations
Contributions
C.F.B. designed the study, conducted the analysis, and wrote the manuscript. M.O. conducted the analysis and wrote the manuscript. J.R.G. designed the study, conducted the analysis, obtained funding for the study, and edited the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Reprints and Permissions
About this article
Cite this article
Breen, C.F., Osborne, M. & Goldstein, J.R. CenSoc: Public Linked Administrative Mortality Records for Individual-level Research.
Sci Data 10, 802 (2023). https://doi.org/10.1038/s41597-023-02713-y
-
Received: 10 July 2023
-
Accepted: 31 October 2023
-
Published: 15 November 2023
-
DOI: https://doi.org/10.1038/s41597-023-02713-y