Abstract
We present a machine vision-based database named GrainSet for the purpose of visual quality inspection of grain kernels. The database contains more than 350K single-kernel images with experts’ annotations. The grain kernels used in the study consist of four types of cereal grains including wheat, maize, sorghum and rice, and were collected from over 20 regions in 5 countries. The surface information of each kernel is captured by our custom-built device equipped with high-resolution optic sensor units, and corresponding sampling information and annotations include collection location and time, morphology, physical size, weight, and Damage & Unsound grain categories provided by senior inspectors. In addition, we employed a commonly used deep learning model to provide classification results as a benchmark. We believe that our GrainSet will facilitate future research in fields such as assisting inspectors in grain quality inspections, providing guidance for grain storage and trade, and contributing to applications of smart agriculture.
Background & Summary
Cereal grains play an essential role in the human diet by providing a diverse range of nutrients1,2, including carbohydrates, dietary fiber and vitamins. Grain kernels are consumed in a variety of food products3, such as bread, pasta and cereals, and serve as raw resources for animal feed, ethanol, adhesives, and other necessities4,5. The inspection of grain kernels prior to processing is a critical step in ensuring the quality, safety and efficiency of the production process6, while also enhancing consumer health and supporting the economic value of cereal crops7. For example, The inspection is a pre-requisite for preventing the spread of harmful contaminants (e.g., mycotoxins8).
Several organizations have established guidelines for the inspection of grain quality. For example, the United States Department of Agriculture (USDA)9 stipulates standards for ensuring grain quality and safety, with specific limits on the acceptable levels of contaminants, such as mold, mycotoxins, and insect parts. Other international organizations, such as the Food and Agriculture Organization (FAO) and the World Health Organization (WHO)10, have also formulated safety and quality guidelines for grains. The standards may vary depending on the region, and individual buyers or processors may have their own quality standards or specifications. Typically, an inspection of grain kernels is performed through physical testing11, sensory evaluation12, and chemical analysis13. Physical testing and sensory evaluation involve measuring the size, weight, or density of kernels, identifying foreign materials or contaminants, as well as checking for physical signs of damage, discoloration, mold growth, or insect infestation on the surface of the kernel. Chemical analysis is conducted to quantitatively determine precise nutritional value and composition, such as moisture, protein, fat and heavy metal content. These methods are crucial in ensuring the safety and overall quality of the final product by detecting potential contaminants or defects in the grain kernels14.
Generally, the majority of inspections can be determined by observing the surface of grain kernels, termed Grain Appearance Inspection (GAI) in this study. GAI mainly involves two aspects: physical characteristics and Damaged & Unsound (DU) grains15. Specifically, physical characteristics pertain to the morphology, size, weight and density of kernels, which are indicators for enhancing processing efficiency and minimizing wastage. DU grains refer to kernels that are damaged or defective, such as moldy, insect-infested, discolored, shriveled, or have heat or moisture damage and physical damage such as cracks or breaks. The proportion of DU grains is one of the essential factors in grain processing, storage and trade. For example, if the percentage of DU grains is less than 2%, the grain samples can be classified as high-quality cereals, while exceeding 12% would render them unusable for human consumption and relegated for usage as animal feed or ethanol production.
However, manually conducting GAI is challenging for inspection accuracy and efficiency due to two main aspects. Firstly, GAI requires inspectors to manually take a volume of grain samples (e.g., 60 grams (g) and near 1,500 kernels for wheat according to established standards16), and inspect them individually in a kernel-by-kernel way. This is a highly labor-intensive and time-consuming process, as inspectors must concentrate on the surfaces of grain kernels. On the other hand, the surfaces of kernels are heterogeneous and inspectors are required to acquire experience in identifying grain kernels from various regions and species. As a result, there are often variances and discrepancies between inspectors from different expertise levels or regions, particularly for those inspectors working in unique geographical and cereal species conditions.
In recent years, several studies have addressed GAI-related challenges by leveraging deep learning techniques. For example, Kozlowski et al.17 collected near 30K barley images, and applied deep convolutional neural networks to perform classification tasks for identifying 4 types of defects. Similarly, Shah et al.18 built a dataset including 1432 images of various barley grains, and proposed an efficient deep learning-based technique that achieved 94% classification accuracy. Furthermore, Fan et al.19 introduced the OOD-GrainSet, including 180K and 40K wheat and maize images respectively. It serves as a benchmark for our-of-distribution detection within the realm of grain quality assessment. Velesaca et al.20 developed the CORN-KERNEL dataset, including near 300 pairs of corn images and annotations. The datasets from these studies are typically restricted to sub-species classification tasks for a single cereal species, and the annotations are confined to only visual and classification information.
In this paper, we present a large-scale database aimed at solving GAI challenges and contributing to the development of smart agriculture. Our database, GrainSet, comprises more than 350K individual kernels of four common types of cereal grains, namely wheat, maize, sorghum and rice, sourced from over 20 regions in four countries. For each kernel, GrainSet provides the surface information in high-resolution images captured by our custom-built prototype device, and experts’ annotations including morphology, physical size, DU grain category and other sample collection information. Moreover, we conduct experiments and provide baselines to validate the effectiveness and quality of GrainSet by employing a deep learning-based method, obtaining average F1-scores exceeding 94% across four types of cereal grains. Utilizing our database, we demonstrate the potential for quantitative analysis from a visual perspective, which has applications in improving crop yield, monitoring quality, accelerating processing time and cost, and ensuring food safety.
Methods
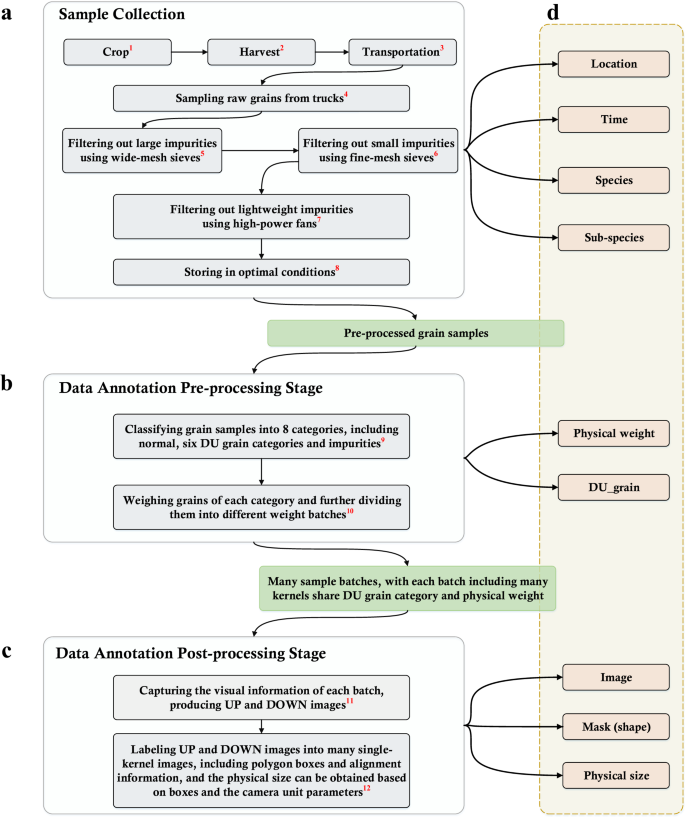
To establish a large-scale and comprehensive database for the purpose of visual quality inspection of grain kernels, we developed a protocol including sample collection, data acquisition and annotations, as shown in Figs. 1, 2. The initial step involves collecting a large volume of cereal grains of diverse characteristics, and then those kernels underwent a series of processes to produce relatively clean samples (see Figs. 1a, 2a). All grain kernels were manually divided by inspectors into many batches based on their DU category and physical weight information (see Figs. 1b, 2b). A prototype device was built to acquire the visual information for grain kernels individually in each batch in a high-efficient way (see Figs. 1c, 2c). Then, all captured images labeled by inspectors and corresponding annotations from data collection and the pre-processing stage are combined as GrainSet (see Figs. 1d, 2d).

Protocol of data collection and annotations for GrainSet. The red superscript of each step corresponds to Fig. 2. (a) Raw cereal grains are sampled from trucks, and undergo a series of processes, including using sieving, high-power fan treatment and storage under optimal conditions. Sample information including location, time, species and sub-species is used as annotations. (b) During the pre-processing stage, inspectors classify grain samples into eight categories, including normal, six types of DU grains and impurities. Each category including many samples is further divided into many groups based on physical weight. The physical weight and DU grain information are used as annotations. (c) In the post-processing stage, inspectors depict kernel shapes and pair UP and DOWN angles. The images, shapes and physical size are used as annotations. (d) Annotations from different stages are stored in the .XML file.

Overview of data collection and annotations for GrainSet. The red superscript of each step corresponds to Fig. 1. (a) GrainSet consists of four common types of cereal grains: wheat, maize, sorghum and rice, and raw cereal grains are collected from over 20 regions in 5 countries. Raw samples undergo a series of processes to remove impurities. (b) Inspectors divided grain kernels into predefined batches, with each batch sharing the same DU grain category and physical weight information. (c) Our prototype device is built to capture the visual information of each batch, producing a pair of high-resolution UP and DOWN images. (d) Inspectors manually depict morphology and align single-kernel images from UP and DOWN angles. All single-kernel images and annotations are combined as GrainSet.
Sample collection of cereal grains
We collected a high quantity of grain kernels across multiple species and regions between the years of 2016 and 2022. Specifically, the collection effort concentrated primarily on the four most prevalent types of cereal grains, namely wheat, maize, sorghum and rice, which together serve as the majority and comprise more than 90% of the world grain cereal production according to the report from the Food and Agriculture Organization of the United Nations in 202221. Raw cereal grains were sampled from over 20 regions within 5 countries ranging from Australia (AU), Cambodia (KHM), Canada (CAN), China (CN) and The United States of America (USA), as illustrated in Fig. 2a. We mainly collected wheat for hexaploid common species (also named the bread wheat) sub-species, maize for popped corn and dent corn sub-species, sorghum for sorghum propinquum sub-species, and rice for Long, Wuchang and Jasmine sub-species.
To ensure the database remains diverse and representative, we collected only a small number of raw cereal grains (with a fixed weight) using skewers from each truck manually, in accordance with sampling guidelines22. The amount of grain sampled is dependent on the physical size and weight of cereal species. Specifically, a laboratory sample of 400 g was extracted from a shipment of 30T (tons) for wheat, a sample of 3000 g from a shipment of 30T for maize, a sample of 200 g from a shipment of 1T for sorghum and a sample of 250 g from a shipment of 20T for shelled rice. All those laboratory samples include near 9,000 kernels individually. In summary, we collected a total of 14,000K wheat kernels, 1,200K maize kernels, 6,000K sorghum kernels and 1,500K rice kernels. Those collected raw grains were further pre-processed and filtered.
Subsequently, following the guidelines established by ISO2433322, the raw grain samples were pre-processed based on a strict protocol, as illustrated in Figs. 1a, 2a. The large and small impurities (such as rock or clay) were filtered out using wide-mesh and fine-mesh sieves respectively, and lightweight impurities (such as bran or roots) were removed using high-power fans. It is noted that there exist impurities and extra matter that cannot be filtered through the above pre-processing protocol, since those impurities have similar shapes and physical weights to grain kernels. Those impurities were determined and labeled by inspectors manually in the annotation step. Finally, the pre-processed samples were stored in depositories that provide optimal conditions in temperature and moisture to ensure their preservation. These samples were then subjected to follow-up visual inspection and physical testing.
Image acquisition device
We further built a prototype device to capture the visual information of the surface of grain kernels. To conduct high-efficiency and high-quality acquisition for the four types of cereal grains, there exist two main challenges. First, given that the physical size of various types of cereal grains is typically small, especially the size of sorghum kernels often being smaller than 4 × 4 × 3 mm3, the tiny size imposes a high demand on the precision of the vision system. Second, due to the heterogeneity of kernels in terms of size and shape, kernels are easily pilled up and often occlude each other, which hinders inspection efficiency.
To address these challenges, we built a machine vision-based prototype device to capture visual information of grain kernels. Our device is able to process a volume of grain kernels simultaneously to achieve a high efficiency of acquisition. It mainly consists of two modules: a feeding module and a visual capturing module, as shown in Fig. 2c. The feeding module was designed to disperse a certain quantity of grain kernels, preventing them from piling up on top of each other. The visual capturing module is then able to capture surface information of those kernels, resulting in efficient and high-quality information acquisition. Specifically, the feeding module is equipped with a vibration belt that delivers pre-processed raw grain kernels, separating them and sequentially transferring them into the visual capturing module. The visual capturing module is equipped with two camera units, and each comprises a high-resolution industrial optical camera with a resolution of 5480 × 3648 pixels, a focal length of 25 mm and an object length of 270 mm, enabling the effective field-of-view to reach 131 mm × 87 mm with close to 860 dots-per-inch. Additionally, the visual capturing module also incorporates circle light resources to provide no-shadow light conditions for capturing high-quality images. Two camera units are arranged vertically to capture visual information of kernels from both top and bottom angles, with a transparent plate that is used to hold all kernels and placed in between the two camera units. The surface information of kernels is captured by the camera units when grain kernels are stationary after being transformed from the feeding module. Due to the heterogeneity of kernel shapes and the presence of concave corners, a smaller region (less than 2%) of the surface may not be captured. In summary, the prototype device can acquire visual information for a batch of grain kernels simultaneously, producing two high-resolution images named UP and DOWN images corresponding to the two camera units.
Image annotations
We built a data annotation protocol to conveniently provide annotation information for grain samples. The protocol consists of pre-processing and post-processing stages. The pre-processing stage is conducted on raw grain samples, as shown in Figs. 1b, 2b. Inspectors manually divided kernels into eight categories including normal, six DU grain categories and impurities (which will be introduced in the next section). Then, samples in each category were further divided into multiple batches based on their physical weights, with a weight interval of 1 mg for each batch. It is noted that the DU grain and physical weight information was annotated by expert inspectors in a laboratory environment equipped with specialized tools (e.g., tweezers and scales), and each annotation was confirmed by at least two independent inspectors through blind validation. As a result, a batch of kernels share the same species, physical weight and DU grain category, and such information serves as the annotations directly when our device captures visual information and produces a pair of UP and DOWN images for this batch.
The post-processing stage was conducted on UP and DOWN images, as shown in Figs. 1c, 2d. To be specific, inspectors manually annotated every kernel in high-resolution images, and each kernel was labeled with a pixel-level polygon box to depict the morphological shape, and then physical size can be calculated according to the shape and fixed field-of-view of the camera units. Subsequently, each high-resolution image can produce a number of single-kernel images based on annotated polygon boxes. For both UP and DOWN images, two sets of polygon boxes can be obtained and are used to localize and crop the visual information of every single kernel from two different angles. To obtain comprehensive visual information for each grain kernel, a straightforward approach is to pair the polygon boxes based on the distance between their centroids. However, in practice, we observed that the kernels in UP and DOWN images may not align perfectly due to inherent machine limitations, and the kernels may shift slightly when transferred from the feeding module to the visual capturing module in some cases. Hence, inspectors manually matched two single-kernel images from both UP and DOWN images. As a result, our GrainSet database contains many single-kernel images and corresponding data collection and annotation information.
Data Records
The GrainSet23,24,25,26,27,28 is deposited on the Figshare under the Creative Commons BY 4.0 license. The whole database includes both processed single-kernel images and annotations. The GrainSet is comprised of four sub-datasets corresponding to different grain types, i.e., wheat, maize, sorghum and rice, with each sub-dataset containing numerous single-kernel images with corresponding annotations. All images are stored in the Portable Network Graphics (PNG) format due to its lossless compression capabilities, in which color information is encoded using the RGB (Red, Green, Blue) color model. It is noted that we zip each sub-dataset as a single file. Additionally, considering that the complete GrainSet is large in disk storage, we randomly select near 2% samples from GrainSet to construct a preview dataset named GrainSet-tiny for a preview of our GrainSet. We additionally release 5% samples of the raw images captured by our acquisition device to create GrainSet-raw, including high-resolution images and comprehensive annotations (e.g., kernel localization information, DU categories). It serves as a reference for understanding the data acquisition and pre-processing procedures.
Statistics of GrainSet
The overview of GrainSet is presented in Table 1. It consists of a total of 352.7K single-kernel images with 200K, 19K, 102.7K and 31K images for wheat, maize, sorghum and rice, respectively. For wheat, we selected 200K wheat kernels from 14,000K raw grain samples that were collected from over 10 regions in 4 countries. To construct a comprehensive database, we maintained the distribution balance in terms of DU grain category and regions, with detailed distributions shown in Fig. 3. However, collecting a significant number of different kinds of DU grain kernels is challenging, as the proportion of DU grains is small. We tried our best to maintain the balance of data distribution in terms of the DU grain category. The normal and DU grains account for 60% and 35% of the total respectively, and the ratio of impurities that are not filtered out through the pre-processing protocol accounts for 5%.

Examples and distributions of sample information in GrainSet. (a) Examples of normal, each kind of DU grains, and impurities for four types of cereal grains. The abbreviations (e.g., NOR) are used in subsequent content. Red lines highlight discriminative regions. (b) Percentages of normal, each kind of DU grains, and impurities for four types of cereal grains. (c) Percentages and numbers of regional information for four types of cereal grains. (d) The inner pie: percentages of four types of cereal grains in GrainSet. The outer pie: percentages of regional information in GrainSet.
Similar to wheat, we selected 19K maize kernels from near 1,200K raw grain samples that were collected from over 6 regions in 2 countries including China and The United States of America. The normal, DU grains and impurities account for near 52%, 32% and 16% of the total respectively. For sorghum, we selected near 102K sorghum kernels from more than 6,000K raw grain kernels that were collected from over 3 regions in China. The normal, DU grains and impurities account for near 58%, 38% and 4% respectively, since the ratio of impurities in raw samples is rare. For shelled rice, we selected 31K rice kernels from 1,500K raw grain samples that were collected from over 4 regions in 2 countries including China and Cambodia. The normal, DU grains and impurities account for near 65%, 29% and 6% respectively. Additionally, we are still updating the database by enriching more grain types and expanding the number of grain samples.
Normal, DU grains and impurities
Each type of cereal grain can be classified into eight categories according to ISO552716. Figure 3a illustrates representative examples of each of the eight categories. For all types of cereal grains, the normal (NOR) grain refers to kernels that have not undergone any sprouting process or other damage. These grains are commonly consumed as staple foods or used in various food products. Impurities (IM) refer to extra materials that cannot be filtered through the data collection protocol.
Among DU grains, the Fusarium & Shriveled (abbreviated F&S) grain indicates kernels infected by fungi belonging to the Fusarium genus. These grains produce toxic substances and have negative effects on safety. The sprouted grain (SD) refers to kernels that have begun the process of germination or sprouting. The moldy grain (MY) refers to grains contaminated with mold or fungi. The broken grain (BN) indicates grains that have been fractured or fragmented during harvesting or transportation. The grain attacked by pests (AP) refers to grains that have been infested by insects. The black point grain (BP) indicates grains (particularly wheat in this study) affected by factors including fungal infections or insect damage. The heated grain (HD) refers to grains (particularly maize and sorghum) that have undergone an unintentional or excessive increase in temperature during storage or processing. The unripe grain (UN) indicates grains (particularly rice) that have not fully reached their maturity or optimal ripeness before being harvested. Among these DU grains, F&S, MY and BP grains have negative effects on health and safety, while SD, BN, AP, HD and UN grains have decreased value.
Annotation files
Each sub-dataset is accompanied by an Extensible Markup Language(.XML) file containing a large number of elements, with an element representing an individual grain kernel and containing a variety of attributes in terms of sample collection and experts’ annotation, as illustrated in Table 2. The ID attribute refers to the unique identifier enabling retrieval of the single-kernel image and the pixel-level binary mask that depicts the shape of the kernel, and all masks are stored in PNG format. The attributes species, sub-species, location and time provide information pertaining to the grain during the sample collection. To avoid potential ethical issues or privacy concerns, any specific region information is erased and location information is presented only at the country level. For experts’ annotation, size is calculated based on the annotated mask. The attributes DU_grain and weight are annotated by expert inspectors during the data annotation pre-processing stage.
Technical Validation
GrainSet is constructed for GAI-related tasks, and multiple real-world GAI applications can be formulated and conducted based on GrainSet. For example, counting the exact number of kernels in a laboratory sample, classifying the types of cereal grains and impurities, and recognizing the DU grains or sub-species. To validate our GrainSet, we conducted classification tasks for recognizing DU grains for all four types of cereal grains, and this task is to classify samples into eight categories including normal, six types of DU grains and impurities.
For each type of cereal species, we randomly split each sub-dataset into training, validation and test sets, with 80%, 10% and 10% proportions respectively by preserving the ratios of normal, each of DU grain categories and impurities, and we denoted such settings as the whole. On the other hand, considering the imbalanced distributions within our database, we also built a balanced sub-set as another training set, in which each category comprises an equal number of images based on the minimum number of images among all DU categories.
To build our classification models, we employed advanced deep convolutional neural networks (CNNs)29, which have achieved remarkable progress in multiple fields including medical image analysis30, industrial applications31, and agriculture32. In this work, we use a widely-used classification model to assess the quality of our database. Our model consists of a backbone and an attention head module, as depicted in Fig. 4a. The backbone employed the classical ResNet-5029 which includes consecutive residual convolutional block and down-sampling convolutional layers to extract semantic features from input images. The attention head module employed a Squeeze-and-Excitation (SE) module33. The SE module consists of channel-wise global pooling operations, fully convolutional layers, and ReLU and sigmoid activation layers, which can adaptively re-calibrate channel-wise feature responses to focus on discriminative regions. Following the success of transfer learning techniques34, we trained four models for four types of cereal grains respectively, and initialized all parameters of backbones by using the models pre-trained on ImageNet35. Then, to fine-tune each classification model, we trained it on a GPU workstation with the PyTorch platform36. The training epoch and batch size were set to 50 and 128. A step learning strategy was employed and an initial learning rate was set to 0.0012, and an SGD optimizer was employed with a weight decay of 0.0001. All input images were resized into 224 × 224 pixels, and data augmentations including random flips, rotations and color jitters were applied. CrossEntropy loss was used as the optimization objective. It is noted that we trained four classification models for four kinds of cereal grains respectively with similar training parameters. Additionally, we conducted experiments to assess the performance of classical and deep network-based methods on our proposed database. For classical methods, we employed color histogram and Scale-Invariant Feature Transform (SIFT)37 for extracting color and texture information, and utilized Support Vector Machine (SVM)38 for classification. For deep networks, we evaluated various network architectures, including VGG1939, Inception-v340, ResNet-5029, ResNet-15229 and Vision Transformer (ViT)41. All training parameters are similar to our model.

Overview of the model and results of technical validation. (a) The detailed structure of our fine-grained classification model. It employs ResNet-50 as the backbone and SE-attention module as the prediction head. (b) The performance of our trained models on test sets for four types of cereal grains. The recall, accuracy and F1-score are reported in the confusion matrix (c) The t-SNE visualization results of features on test sets for four types of cereal grains.
The performance comparison of classical methods, various network backbones and our model under both whole and balanced settings is presented in Table 3. It can be seen that employing the whole setting achieves better performance compared to the counterparts using the balanced setting. This is because there are many more training samples with the whole setting, which can substantially benefit feature learning. Given the extreme imbalance between normal and DU cereal grains in actual scenarios, we recommend that future work approach the issue from the perspective of addressing this imbalance. Using color histograms and SIFT as feature extractors yield 70.6% and 35.5% macro F1-scores on the whole setting respectively. Deep networks-based methods show obvious improvements, in which ResNet-152 achieves the best performance of 96.4% and 96.1% average accuracy and macro F1-score respectively. Compared to these methods, the detailed performance of our models is illustrated in Fig. 4b, where we show the confusion matrix, recall, accuracy and F1-score together. It can be observed that our models produced remarkable classification results, achieving average F1-scores of 99.9% for wheat, 97.2% for maize, 96.8% for sorghum and 94.1% for rice respectively. We also visualized qualitative results to further validate our results, as shown in Figs. 4c, 5. Specifically, we employed the t-SNE technique42 to visualize the intermediate features that are compressed and extracted from the output of the SE attention head. We observed that normal, different kinds of DU grain categories and impurities are distinctly separated in the feature space, verifying the quality of our GrainSet. We also employed the Gard-CAM technique43 to visualize the activated areas where our trained models focus on the input images. It can be observed that our model can effectively focus on the discriminate regions with distinct characteristics of DU grains. For example, our models can concentrate on moldy spots, wormholes and broken parts for four types of cereal grains. Overall, our experimental results demonstrate the quality of our GrainSet.

The Gard-CAM visualization results extracted from our trained models, and red lines highlight the discriminative regions.
Code availability
The validation code and models are released in the Github repository https://github.com/GrainSpace/GrainSet. We conducted benchmark analysis using PyTorch and OpenCV, and all parameters used in our implementation are reflected in the repository.
References
-
McKevith, B. Nutritional aspects of cereals. Nutrition Bulletin 29, 111–142 (2004).
Google Scholar
-
Stevenson, L., Phillips, F., O’sullivan, K. & Walton, J. Wheat bran: Its composition and benefits to health, a European perspective. International Journal of Food Sciences and Nutrition 63, 1001–1013 (2012).
Google Scholar
-
Charalampopoulos, D., Wang, R., Pandiella, S. & Webb, C. Application of cereals and cereal components in functional foods: a review. International Journal of Food Microbiology 79, 131–141 (2002).
Google Scholar
-
Abuajah, C. I., Ogbonna, A. C. & Osuji, C. M. Functional components and medicinal properties of food: A review. Journal of Food Science and Technology 52, 2522–2529 (2015).
Google Scholar
-
Bigliardi, B. & Galati, F. Innovation trends in the food industry: The case of functional foods. Trends in Food Science & Technology 31, 118–129 (2013).
Google Scholar
-
Evers, T. & Millar, S. Cereal grain structure and development: Some implications for quality. Journal of Cereal Science 36, 261–284 (2002).
Google Scholar
-
Cassman, K. G., Dobermann, A., Walters, D. T. & Yang, H. Meeting cereal demand while protecting natural resources and improving environmental quality. Annual Review of Environment and Resources 28, 315–358 (2003).
Google Scholar
-
Placinta, C., D’Mello, J. F. & Macdonald, A. A review of worldwide contamination of cereal grains and animal feed with fusarium mycotoxins. Animal Feed Science and Technology 78, 21–37 (1999).
Google Scholar
-
United States Department of Agriculture: Grain standards, https://www.ams.usda.gov/grades-standards/grain-standards (2023).
-
Food and Agriculture Organization of the United Nations & World Health Organization: Codex alimentarius international food standards, https://www.fao.org/fao-who-codexalimentarius/codex-texts/list-standards/en/ (2023).
-
Rasper, V. F. & Walker, C. E. Quality evaluation of cereals and cereal products (CRC Press, 2000).
-
Vithu, P. & Moses, J. Machine vision system for food grain quality evaluation: A review. Trends in Food Science & Technology 56, 13–20 (2016).
Google Scholar
-
Serna-Saldivar, S. O. Cereal grains: Properties, processing, and nutritional attributes (CRC press, 2016).
-
Patrcio, D. I. & Rieder, R. Computer vision and artificial intelligence in precision agriculture for grain crops: A systematic review. Computers and Electronics in Agriculture 153, 69–81 (2018).
Google Scholar
-
Moss, A. & Green, P. Sand and silt grains: Predetermination of their formation and properties by microfractures in quartz. Journal of the Geological Society of Australia 22, 485–495 (1975).
Google Scholar
-
ISO 5527: Cereals–Vocabulary, https://www.iso.org/standard/50933.html. Standard, International Organization for Standardization (2015).
-
Kozłowski, M. & Szczypin´ski, P. M. barley defects identification by convolutional neural networks. In Information Technology in Biomedicine, 187–198 (2019).
-
Shah, S. A. A. et al. Automatic and fast classification of barley grains from images: A deep learning approach. Smart Agricultural Technology 2, 100036 (2022).
Google Scholar
-
Fan, L. et al. Identifying the defective: Detecting damaged grains for cereal appearance inspection. In European Conference on Artificial Intelligence, 660–667 (2023).
-
Velesaca, H. O., Mira, R., Suárez, P. L., Larrea, C. X. & Sappa, A. D. Deep learning based corn kernel classification. In IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 294–302 (2020).
-
FAO. World Food Situation, https://www.fao.org/worldfoodsituation/csdb/en. Tech. Rep. (2023).
-
ISO 24333: Cereals and cereal products – Sampling, https://www.iso.org/standard/42165.html. Standard, International Organization for Standardization (2009).
-
Fan, L. wheat.zip, Figshare, https://doi.org/10.6084/m9.figshare.22992317.v2 (2023).
-
Fan, L. maize.zip, Figshare, https://doi.org/10.6084/m9.figshare.22987562.v2 (2023).
-
Fan, L. sorghum.zip, Figshare, https://doi.org/10.6084/m9.figshare.22988981.v2 (2023).
-
Fan, L. rice.zip, Figshare, https://doi.org/10.6084/m9.figshare.22987292.v3 (2023).
-
Fan, L. GrainSet-tiny.zip, Figshare, https://doi.org/10.6084/m9.figshare.22989029.v1 (2023).
-
Fan, L. GrainSet-raw, Figshare, https://doi.org/10.6084/m9.figshare.24137472.v1 (2023).
-
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770–778 (2016).
-
Fan, L., Sowmya, A., Meijering, E. & Song, Y. Cancer survival prediction from whole slide images with self-supervised learning and slide consistency. IEEE Transactions on Medical Imaging 42, 1401–1412 (2023).
Google Scholar
-
Bergmann, P., Fauser, M., Sattlegger, D. & Steger, C. MVTec AD–a comprehensive real-world dataset for unsupervised anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 9592–9600 (2019).
-
Fan, L. et al. GrainSpace: A large-scale dataset for fine-grained and domain-adaptive recognition of cereal grains. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 21116–21125 (2022).
-
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7132–7141 (2018).
-
Zhuang, F. et al. A comprehensive survey on transfer learning. Proceedings of the IEEE 109, 43–76 (2020).
Google Scholar
-
Deng, J. et al. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 248–255 (2009).
-
Paszke, A. et al. Pytorch: An imperative style, high-performance deep learning library. Advances in Neural Information Processing Systems 32, 8024–8035 (2019).
-
Lowe, D. G. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision 60, 91–110 (2004).
Google Scholar
-
Hearst, M., Dumais, S., Osuna, E., Platt, J. & Scholkopf, B. Support vector machines. IEEE Intelligent Systems and their Applications 13, 18–28 (1998).
Google Scholar
-
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014).
-
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J. & Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2818–2826 (2016).
-
Dosovitskiy, A. et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. In International Conference on Learning Representations (2020).
-
Maaten, L. V. D. & Hinton, G. Visualizing data using t-SNE. Journal of Machine Learning Research 9, 2579–2605 (2008).
Google Scholar
-
Selvaraju, R. R. et al. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, 618–626 (2017).
Author information
Authors and Affiliations
Contributions
L.F. and Y.S. conceived and led the expedition. L.F., Y.D., D.F., Y.W. developed data protocols, implemented the image analysis methods, and collected the raw data. M.P. provided further technical and scientific advice to the project. L.F., Y.D. and Y.S. drafted the manuscript, and all authors reviewed and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Reprints and Permissions
About this article
Cite this article
Fan, L., Ding, Y., Fan, D. et al. An annotated grain kernel image database for visual quality inspection.
Sci Data 10, 778 (2023). https://doi.org/10.1038/s41597-023-02660-8
-
Received: 11 July 2023
-
Accepted: 18 October 2023
-
Published: 08 November 2023
-
DOI: https://doi.org/10.1038/s41597-023-02660-8