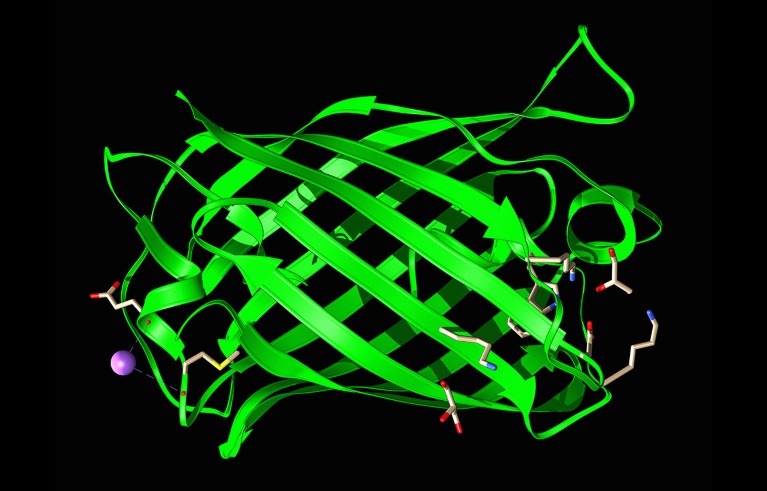

A structural model of green fluorescent protein, a workhorse of biotechnology.Credit: Laguna Design/Science Photo Library
An artificial intelligence (AI) model that speaks the language of proteins — one of the largest yet developed for biology — has been used to create new fluorescent molecules.
The proof-of-principle demonstration was announced this month by EvolutionaryScale in New York City, alongside US$142 million in new funding to apply its model to drug development, sustainability and other pursuits. The company, launched by scientists who previously worked at tech giant Meta, is the latest entrant in an increasingly crowded field that is applying cutting-edge machine-learning models trained on language and images to biological data.
AI tools are designing entirely new proteins that could transform medicine
“We want to build tools that can make biology programmable,” says Alex Rives, the company’s chief scientist, who was part of Meta’s efforts to apply AI to biological data.
EvolutionaryScale’s AI tool, called ESM3, is what’s known as a protein language model. It was trained on more than 2.7 billion protein sequences and structures, as well as information about these proteins’ functions. The model can be used to create proteins to specifications provided by users, akin to the text spit out by chatbots such as ChatGPT.
“It’s going to be one of the AI models in biology that everybody’s paying attention to,” says Anthony Gitter, a computational biologist at the University of Wisconsin–Madison.
Glowing up
Rives and his colleagues worked on earlier iterations of the ESM model at Meta, but struck out on their own last year, after Meta ended its work in this area. They had previously used the model ESM-2 to create a freely available database of 600 million predicted protein structures1. Other teams have since used versions of ESM-1 to design antibodies with improved activity against pathogens including SARS-CoV-22 and to re-engineer ‘anti-CRISPR’ proteins to improve the efficiency of gene-editing tools3.
This year, another biology AI company, Profluent in Berkeley, California, used its own protein language model to create new CRISPR-inspired gene-editing proteins, and made one such molecule freely available for use.
To demonstrate its latest model, Rives’ team set out to overhaul another biotechnology workhorse: the green fluorescent protein (GFP), which absorbs blue light and glows green. Researchers isolated GFP in the 1960s, from the bioluminescent jellyfish Aequorea victoria. Later work — which, with the discovery, was recognized with a Nobel prize — showed how GFP could label other proteins viewed under a microscope, explained the molecular basis for its fluorescence and developed synthetic versions of the protein that glowed much more brightly and in different colours.
Researchers have since identified other similarly shaped fluorescent proteins, all sharing a light-absorbing and emitting ‘chromophore’ core surrounded by a barrel-shaped scaffold. Rives’ team asked ESM3 to create examples of GFP-like proteins that contained a set of key amino acids found in GFP’s chromophore.
The researchers synthesized 88 of the most promising designs and measured their ability to fluoresce. Most were duds, but one design, dissimilar to known fluorescent proteins, glowed faintly — about 50 times weaker than natural forms of GFP. Using this molecule’s sequence as a starting point, the researchers tasked ESM3 with improving on its work. When the researchers made around 100 of the resulting designs, several were as bright as natural GFPs, which are still vastly dimmer than lab-engineered variants.
One of the brightest ESM3-designed proteins, dubbed esmGFP, is predicted to have a structure resembling those of natural fluorescent proteins. However, its amino-acid sequence is vastly different, matching less than 60% of the sequence of the most closely related fluorescent protein in its training data set. In a preprint posted on the server bioRxiv4, Rives and his colleagues say that based on natural mutation rates, this level of sequence difference equates to “over 500 million years of evolution”.
But Gitter worries that this comparison is an unhelpful, and potentially misleading, way of describing the product of a cutting-edge AI model. “It sounds scary when you think about AI and accelerating evolution,” he says. “I feel like overhyping what a model does can hurt the field and it can be dangerous for the public.
Rives sees ESM3’s generation of new proteins by iterating through various sequences as analogous to evolution. “We think the perspective of what it would take for nature to generate something like this is an interesting one,” he adds.
Risk threshold
ESM-3 is among the first biological AI models to use enough computing power during its training to require developers to notify the US government and report risk-mitigation measures, under a 2023 presidential executive order. EvolutionaryScale says it has already been in touch with the US Office of Science and Technology Policy.
Could AI-designed proteins be weaponized? Scientists lay out safety guidelines
The version of ESM3 that eclipsed that threshold — comprising nearly 100 billion parameters, or variables the model uses to represent relationships between sequences — is not publicly available. For a smaller open-source version, certain sequences, such as those from viruses and a US government list of worrying pathogens and toxins, were excluded from training. Neither can ESM3-open — which scientists anywhere can download and run independently — be prompted to generate such proteins.
Martin Pacesa, a structural biologist at the Swiss Federal Institute of Technology in Lausanne, is excited to begin working with ESM3. It is one of the first biological models to allow researchers to specify designs using natural-language descriptions of its properties and functions, he notes, and he is eager to see how this and other features perform experimentally.
Pacesa is impressed that EvolutionaryScale released an open-source version of ESM3, and a clear description of how the largest version was trained. But the largest model would take immense computing resources to develop independently, he says. “No academic lab will be able to replicate it.”
Rives is eager to apply ESM-3 to other designs. Pacesa, who was part of the team that used a different protein language model to make new CRISPR proteins, says it will be interesting to see how ESM-3 does at this. Rives envisions applications in sustainability — a video on their website shows the design of plastic-eating enzymes — and in the development of antibodies and other protein-based drugs. “It’s really a model at the frontier,” he says.