Abstract
China contributed nearly one-fifth of the world maize production over the past few years. Mapping the distributions of maize cropland in China is crucial to ensure global food security. Nonetheless, 10 m maize cropland maps in China are still unavailable, restricting the promotion of sustainable agriculture. In this paper, we collect numerous samples to produce annual 10-m maize cropland maps in China from 2017 to 2021 with a machine learning based classification framework. To overcome the temporal variations of plants, the proposed framework takes Sentinel-2 sequence images as input and utilizes deep neural networks and random forest as classifiers to map maize in a zone-specific way. The generated maps have an overall accuracy (OA) spanning from 0.87 to 0.95 and the maize-cultivated areas estimated by the maps are highly consistent with the records in statistical yearbooks (R2 varying from 0.83 to 0.95). To the best of our knowledge, this is the first annual 10-m maize maps across China, which largely facilitates the sustainable agriculture development in China dominated by smallholder farmlands.
Background & Summary
Due to the soaring population and diminishing resources, the world is facing a potential food shortage crisis, where around 70% more food will be needed for human consumption in 2050, as compared to consumption today1. The situation could be more urgent in developing countries2. Hence, food security is highlighted as a prior sustainable development goal by the United Nation3. As one of the top three staple food, maize is cultivated worldwide, with China being one of the top three maize-producing countries. Due to its underdeveloped agriculture management, China, which contributes about 1/5 of the production of global maize, could be an uncertain factor in the global maize trade4. Thus, understanding the maize planting pattern of China can be of great significance to facilitate agriculture management and ensure food security.
Recently, GlobeLand305 and FROM-GLC106 have made great progress in land use mapping. However, compared to landcover mapping, the identification of crops is more complex due to the confusing textures and mixed pixels in the coarse-resolution images. By collecting spatial-temporal information of various crops, remote sensing imagery is able to map the changes of crops, which provides an effective tool to simplify agriculture management. For example, to facilitate the management of agriculture, existing mapping produces such as the Cropland Data Layer7 (CDL) in the US, and the Agriculture and Agri-Food Canada’s Annual Crop Inventory8 (AAFC) have been widely used for crop yield estimation9, land use change detection10, and crop monitor11. Nevertheless, both CDL and AAFC products are derived from Landsat imagery. In certain regions with small cultivation areas, they may struggle to distinguish different crop species accurately. With a 10-meter spatial resolution and a 5-day revisit cycle frequency, Sentinel-2 is able to reduce mixed pixels and provide rich phenological information for different crop types, which has the potential to increase mapping accuracy. Considerable efforts have been made to generate high-resolution maps of various crops. Zheng et al.12 successfully mapped the distribution of sugarcane in China utilizing long-term Sentinel-2 sequences. Similarly, Pan et al.13 achieved the identification of double-cropped rice distribution in the Southeast region by discriminating the reflectance differences in Sentinel-1 data. By integrating Landsat and Sentinel-2 imagery, Dong et al.14 generated high-resolution maps of winter wheat in China.
There are a few works specifically designed for maize mapping with remote sensing data, Shen et al.15 and Peng et al.16 utilized time-weighted dynamic time warping to discriminate maize from other agricultural crops, resulting in the production of 30-meter resolution maize maps. With the help of the Sentinel-2B satellite launched in 2017, You et al.17 produced 10-m maps for maize from 2017 to 2019 in Northeast China with the help of random forest. A similar approach was adopted to map 10-m maize distribution in the Heihe River basin of China18 and Makarfi in Northern Nigeria19. Wang et al. adopted a parcel-based method to extract maize in Jiaozuo (a province of China) by fusing the Sentinel-1 and Sentinel-2 images19. However, most of the approaches are applied in small-scale areas, A maize distribution product in China based on a 10-meter spatial resolution has not yet emerged in the current literature due to three potential issues. First, unlike the intensive croplands in developed countries, most agriculture in China is in the form of smallholdings with irregular planting patterns and uncertain farm sizes, which may impede maize mapping20,21. Second, the lack of ground truth labels and the interference of noise may decrease the performance of mapping dramatically. Third, due to the spatial-temporal variations, the models trained in one area may perform poorly in the other areas.
To address the above issues, our contributions are three-fold: (1) we collected plenty of samples with ground truth labels across China by field investigation, resolution image interpretation, and the information inferred from statistic yearbooks; (2) To address the problem of spatial and temporal variations, we proposed a recurrent neural network to fully extract temporal features and reduce intra-class variations based on discriminative loss functions; (3) To prevent over-fitting, we adopt zone-specific random forest algorithm in areas with scarce samples. Finally, the maize maps in China at 10-m spatial resolution are obtained for a total of 5 years, from 2017 to 2021. The experimental results indicate that the proposed method is able to generate high-resolution maize maps with reliable accuracy in China dominated by smallholder farmland.
Methods
Study area
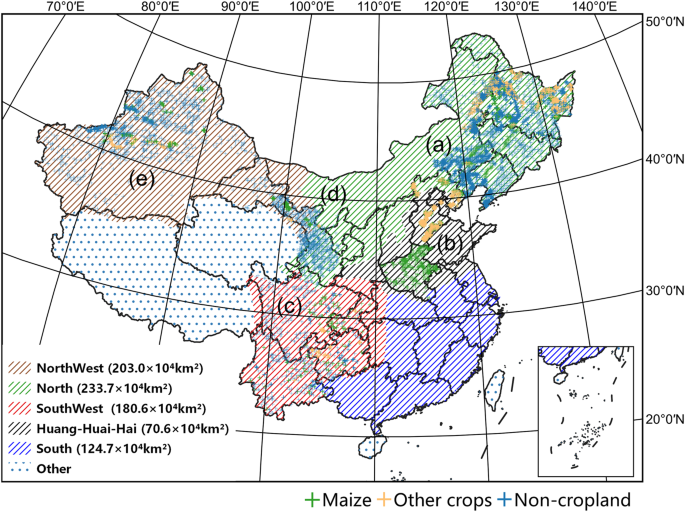
The maize-cultivated areas in China are divided into five regions according to local climate and farming practice22, i.e., North, Huang-Huai-Hai, Southwest, Northwest and South. According to the China Statistical Yearbook23,24,25,26,27, the five study areas cover more than 99.9% of China’s maize planting regions, as shown in Fig. 1.
The climatic conditions in these cultivation zones in China are distinctive. The North China zone experiences a temperate continental climate with cold winters and warm summers. The Huang-Huai-Hai zone has a warm-temperate and semi-humid climate, with distinct seasons and abundant rainfall. The Southwest and Southern China zones have a subtropical monsoon climate with abundant rainfall and high temperatures, while the Northwest region has a temperate continental arid and semi-arid climate with low precipitation and large temperature variations between day and night. Due to natural conditions, five maize-cultivated zones have different cropping systems. For example, maize in the northern regions mainly matures once a year, while in the southern regions, it may mature 2-3 times a year. This inspires us to adopt different models to map maize in different regions.
The maize mapping procedure
The agricultural landscape in China is dominated by smallholder farmlands4, where the size of the cropland depends heavily on agroecological and economic environments. In small-scale farmlands, it is hard to identify crop types based on the texture features extracted from images of 10-meter spatial resolution with mixed pixels. Hence, we use the time-series data of Sentinel-2 (S2) imagery as the input to the classification models to extract hierarchical temporal representations. The overview of the framework is shown in Fig. 2, which comprises the following four primary steps, i.e., image pre-processing, sample collecting, classification, and post-processing.
-
(1) The image pre-processing step includes band selection, cloud removal, multi-temporal image synthesis, and visual interpolation of samples. More details can be found in the ‘Sentinel-2 images pre-processing’ section.
-
(2) In the second step, we collected 79255 ground truth labels from five maize-cultivated zones from 2017 to 2021. Four sample collection methods are described in the ‘Sample collection’ section.
-
(3) The third step involves model selection and map generation, where different machine learning models are chosen for different regions, and multi-year maize planting distribution products are obtained. To prevent overfitting, for planting zone (a) with sufficient samples, we propose a deep learning-based model to identify the plants. For plants in other areas (zones b, c, d, e) with limited samples, we categorize plants by adopting the zone-specific random forest model. The maize classification models are introduced in the ‘The classification model’ section.
-
(4) The final step is the post-processing procedure, which involves removing speckle points by a circular kernel-based majority filter with a radius of 10 m and masking the maize maps with coarser resolution corn maps. More details can be found in the ‘Post-processing’ section.
Sentinel-2 image pre-processing
We used the Sentinel-2 top-of-atmosphere (TOA) reflectance images (Level-1C)28 acquired from 2017 to 2021 in China as the input for classification tasks. To reduce the spectral redundancy of the images and improve the efficiency of the proposed method, the Pearson correlation coefficients of the different spectral on maize samples are calculated to remove the bands with correlations greater than 0.98, as shown in Fig. 3. The threshold is manually selected used to filter out strongly linearly correlated features. Eventually, 8 S2 image channels, including blue, green, red, red edge1, red edge2, near-infrared (NIR), shortwave-infrared (SWIR)-1 and SWIR-2 channels, were employed for classification. To accelerate model convergence29,30, two more channels with widely-used spectral indices, i.e., normalized vegetation difference index (NDVI)31 and enhanced vegetation index (EVI)32 are stacked with images and adopted as input for maize mapping. The indices are calculated according to Eqs. 1–2
where ({rho }_{nir},{rho }_{red},{rho }_{blue}) represent the near infra-red, red, and blue bands of the S2 imagery respectively.
According to the characteristics of the maize phenological22,33, we collect images in seven months from April to October (Day of Year (DOY): 90–300) to generate maize mapping. To avoid the accuracy loss caused by cloud contaminations, the adjusted cloud score algorithm34 is used to detect and remove clouds. Specifically, the cloud score is the weighted sum of the bright, moist, and snow indices, computed by six bands (aerosols, blue, green, red, nir, and swir). The algorithm34 initially detects relatively brighter areas using four spectral bands (blue, aerosols, red, and green) and subsequently calculates a cloud score by taking a weighted sum of two indices, i.e., Normalized Difference Snow Index (NDSI) and Normalized Difference Moisture Index (NDMI), as defined in Eqs. 3, 4. These two indices are computed using three spectral bands (green, red, and shortwave-infrared). To recover the areas covered by cloud, we synthesize S2 images using median values for each 30-day interval. Then the missing pixels are filled by linearly interpolating using images from the preceding and succeeding months.
where the ({rho }_{green},{rho }_{swir},{rho }_{red}) denote the green, short-wave infrared and red bands of remote sensing imagery.
Sample collection
As shown in Fig. 1, the samples are collected from 2017 to 2021 in four study areas with five regions, i.e., (a) North China, (b) Huang-huai-hai, (c) Southwest China, (d) Gansu province and (e) Xinjiang province. Since southern China contributes about 3% of maize planting areas according to the China statistical yearbook, it is hard to collect samples in these areas with on-site surveys Thus, we incorporate samples from the adjacent Southwest China (c) and Huang-Huai-Hai (b) regions to perform classification in southern China. The images are acquired from the Sentinel-2 satellite with samples categorized into three classes, i.e., maize, non-maize and non-cropland, and the number and the distributions of the samples are shown in Tables 1, 2, respectively. The quality of maize samples has a significant impact on the model performance. However, as discussed in Sec. Background and Summary, it is difficult to obtain accurate samples from satellite imagery due to the confusing textures and color features among crop species. Therefore, the samples are collected in the following four ways to guarantee the quality of the samples.
-
(I) The samples collected by field surveys. We record the positions and species of ground samples by mobile GPS devices. The records of the samples are inspected visually and adjusted manually according to the high-resolution remote sensing imagery.
-
(II) The samples indirectly obtained through the statistical yearbooks of China. As field surveys are labor-intensive and time-consuming, we generate non-maize samples with the facilitation of the statistical yearbook23,24,25,26,27, which contains detailed crop yield records for each county. We assume that the counties without maize-planting records for the past ten years do not have maize-planting farmlands. Then, the collected sample points from the farmlands in these counties are categorized as non-maize.
-
(III) The samples derived from existing products. To prevent overfitting, we increase the number of samples by gathering maize and non-maize samples from the Xinjiang and Gansu maize mapping products35 from local agriculture departments in 2020.
-
(IV) The samples derived from visual interpreting. The non-cultivated land samples are collected according to the color and texture characteristics of the plants in the multi-phase Sentinel-2 imagery.

The overview of the collected samples in China. Different textured backgrounds represent different agro-ecological zones, divided into North, Northwest, SouthWest, Huang-Huai-Hai, and South regions. (a–e) denote the distributions of the samples in North China, Huang-huai-hai, Southwest China, Gansu Province and Xinjiang province, respectively.

The overview of our maize mapping framework.

The Pearson correlation analysis of various bands of S2 imagery.
The classification model
The proposed deep learning model for maize classification
The flowchart of the proposed deep learning-based maize mapping method is shown in Fig. 4. The network architecture mainly consists of two modules, i.e., the feature extraction and classification modules. The input of the network is a sequence of multi-temporal pixels covering the region of interest, which consists of spectral signatures of 8 wavelength bands and the NDVI and EVI indices.

The proposed deep learning model in the maize mapping framework. “ + ” and “×” denote the pointwise addition and multiplication, respectively.
The input data point can be denoted as Im,s = I4,1, I4,2, I4,3, I4,4, I4,5, I4,6, I4,7, I4,8, I4,9, I4, 10, where m is the month of the maize growth phenology (from April to October) and s is the spectral index for different bands (Blue, Green, Red, Red Edge1, Red Edge2, NIR, SWIR-1, SWIR-2, NDVI, and EVI).
The feature extractor module consists of a two-layer recurrent neural network (RNN)36 to extract temporal information, while the classification module is constructed with two fully connected layers. To be specific, we utilize an RNN with gated recurrent units (GRUs) as the gating mechanism, which has demonstrated superior performance on smaller datasets37. The classification module uses a sigmoid activation function at the output layer to predict the class probabilities of maize, other crops, and non-cropland.
The model is optimized using the Adam algorithm38. We adopt a cross-entropy loss and a center loss as the objective functions. The cross-entropy loss (Lce) is calculated by comparing the predicted class probabilities with the ground truth labels of the input data, as shown in Eq. 5. To further improve the discriminative power of the learned features, the network also employs the center loss regularization term39 (Lcenter) to minimize the distance of the intra-class features (Eq. 6). In other words, it encourages the features to be close to the centers of their respective classes, making the features more discriminative. This is achieved by minimizing the Euclidean distance between the feature vector of each input sample and the center of its corresponding class, as shown in Eq. 7. The combination of cross-entropy loss and center loss allows the model to optimize both the classification accuracy and the feature representation simultaneously, resulting in a more robust and accurate model. The cross-entropy and center losses are defined as:
where N is the number of samples, C is the number of classes, yi, j denotes the ground truth label of the i-th sample for the j-th class, and ({widehat{y}}_{i,j}) is the predicted probability of the i-th sample for the j class. ({f}_{left({x}_{i}right)}) represents the deep feature of the i-th sample, ({c}_{{y}_{i}}) represents the center feature of the yi-th class, and ||·||2 is the Euclidean distance. The weights of the two losses, denoted by w1 and w2, were set to 1.0 and 0.001, respectively.
To evaluate the proposed method, the collected samples are randomly divided into training, validation, and testing samples with a ratio of 70:10:20. To avoid overfitting, the optimal model with the best overall accuracy on the validation set will be applied to generate maize maps. During the training process, the batch size is set to 50 and the learning rate is 0.001.
The zone-specific random forest model
Random forest algorithm40 ensembles a mass of decision trees to obtain the most convincing predictions. Compared to deep learning-based model22, the random forest model can achieve better performance with less consumption for the classification and regression tasks with limited labels. Hence, we adopt a random forest model to extract maize from remote sensing imagery in the regions outside of Northeast China. To address the problem of spatial variation, we utilized the samples within each region to train the random forest model specific to that region. Then the trained model is used to predict the maize distribution in the given region. The classification task is performed on the Google Earth Engine (GEE) platform41, which has been successfully used to perform crop classification42, crop yield regression43, etc. On the GEE platform, we configured the number of trees to 200 while keeping the remaining parameters at their default values.
Post-processing
For large-scale and high-resolution maize mapping, the speckle noise is inevitable. The speckle noise typically refers to small, scattered misclassifications or noise present in the generated maps, which is mainly caused by inherent challenges in remote sensing imagery, which can be influenced by atmospheric conditions, sensor noise, and illumination variations. We apply the circular kernel-based majority filter with a 10-meter radius to remove the speckles42, which means that the predicted maize patches smaller than 100 square meters are removed. In addition, since predicting all crops in the northwest region with only a few samples is challenging, we introduce the ChinaCropPhen1km maize distribution product44 at a spatial resolution of 1 km to facilitate maize mapping. The ChinaCropPhen1km product is utilized as a mask to filter out the pixels incorrectly identified as maize in Northwest China. Specifically, the maize pixels located beyond the 1 km outward buffer of the ChinaCropPhen1km product are filtered out.
Data Records
Five 10-m maize cropland maps of are generated for planting areas of China from 2017–2021. The data records are shared in the figshare, which is an online open access repository for publishing research data. As the 10-meter resolution product is quite large, we have separated and saved it according to the administrative division codes (adcode). This data set consists of 145 files. The files are named according to the format ‘[adcode]_[year].tif’45.
Technical Validation
The generated maize maps are evaluated from two aspects, i.e., (1) the overall classification accuracy on the testing datasets, and (2) the consistency between the maize-planting areas estimated based on the proposed method and the ones recorded in the statistic yearbooks.
(1) For each maize-cultivated zone, the model with the highest overall accuracy (OA) in the validation set is adopted to predict the labels in the testing set. The sizes of testing set in different zones are 7266(a),1024(b), 910(c), 500(d) and 532(e), respectively. Four matrices, including user accuracy, producer accuracy, overall accuracy, and kappa coefficient46, are used to evaluate the accuracy of the generated maps. The evaluation results of the deep learning and random forest models are shown in Table 3. We can observe that the OAs of the five zones vary from 0.83 to 0.95.
Since the training and testing samples are not acquired in the same year, the performance of the proposed framework may vary in different years due to phenology variations. To validate the robustness of the proposed framework, we conduct experiments in region (a) that owns samples of multiple years. As shown in Table 4, we selected two years from 2017,2018, and 2019, using the samples in one year as training data and the samples in other year as testing data, to validate the performance of the model. The accuracy of the prediction is slightly decreased (on average, the overall accuracy is 0.85), but still maintains a good accuracy, demonstrating the feasibility of the proposed framework.
(2) To further evaluate the proposed framework, the maize-planting areas derived from the annual maize maps are compared with the ones recorded in the statistic yearbooks from 2017 to 2021. Specially, we re-project the annual maps as WGS 1984 Albers for Northern Asia (EPSG: 102025) on the GEE platform to ensure the area units are the same as the yearbook. As shown in Fig. 5, the average coefficient of determination (R2) is 0.91, with a high value of 0.95 in 2020. These findings indicate that our products are consistent with the statistical yearbook records. The spatial details of the maize maps from 2017 to 2021 is shown in Fig. 6. We can observe that the accuracy is poorer in the provinces located in southern and northwestern China, where there were less number of sample points. The accuracy is higher in Northeast China and Huang-Huai-Hai regions, where there are more sample points. This indicates that the level of uncertainty is mainly caused by the number of sample points, which is a limitation of data-driven models. In the future, we plan to improve our approach by combining data-driven and mechanism-driven models.

The estimated maize planting area from our annual maize maps with the statistical data at the province level in 2017, 2018, 2019, 2020 and 2021.

The spatial details of the maize maps from 2017 to 2021.
Usage Notes
China is the second-largest maize-producing country in the world. As a developing country dominated by smallholder farmlands and underdeveloped agriculture management, the maize planting areas of China can be easily affected by global climate change47, unbalanced economic development48, etc. Quantifying the distribution of maize in China is of great significance to global food security. In this paper, we collected 79255 ground truth labels in China and proposed a machine learning based maize classification framework. Then we generate maize maps with a resolution of 10 meter from 2017 to 2021 (Fig. 6). According to the experiments, the maize-planting areas derived from the maize maps are highly consistent with the records in the statistical yearbooks. Therefore, the produced maps can be readily used for agricultural yield estimation and intensive agriculture development. The data is available as binarized spatial raster data, making it simple to be utilized with other products for mathematical and spatial operations. Additionally, our datasets can provide reference and uncertainty analysis for other similar products in Table 5.
Code availability
The code utilized for maize mapping is open-source and will be published on GitHub (https://github.com/lixingang/ChinaMaizeCls) and along with the maize maps45 (https://doi.org/10.6084/m9.figshare.22689751.v17).
References
-
Cole, M. B., Augustin, M. A., Robertson, M. J. & Manners, J. M. The science of food security. npj Science of Food 2, 14 (2018).
Google Scholar
-
Shiferaw, B., Prasanna, B. M., Hellin, J. & Bänziger, M. Crops that feed the world 6. past successes and future challenges to the role played by maize in global food security. Food security 3, 307–327 (2011).
Google Scholar
-
Prosekov, A. Y. & Ivanova, S. A. Food security: The challenge of the present. Geoforum 91, 73–77 (2018).
Google Scholar
-
Zhang, W. et al. Closing yield gaps in china by empowering smallholder farmers. Nature 537, 671–674 (2016).
Google Scholar
-
Chen, J., Cao, X., Peng, S. & Ren, H. Analysis and applications of globeland30: a review. ISPRS International Journal of Geo-Information 6, 230 (2017).
Google Scholar
-
Gong, P. et al. Stable classification with limited sample: transferring a 30-m resolution sample set collected in 2015 to mapping 10-m resolution global land cover in 2017. Science Bulletin 64, 370–373, https://doi.org/10.1016/j.scib.2019.03.002 (2019).
Google Scholar
-
Boryan, C., Yang, Z., Mueller, R. & Craig, M. Monitoring us agriculture: the us department of agriculture, national agricultural statistics service, cropland data layer program. Geocarto International 26, 341–358 (2011).
Google Scholar
-
Fisette, T. et al. Aafc annual crop inventory. In 2013 Second International Conference on Agro-Geoinformatics (Agro-Geoinformatics), 270–274 (IEEE, 2013).
-
Jiang, H. et al. A deep learning approach to conflating heterogeneous geospatial data for corn yield estimation: A case study of the us corn belt at the county level. Global change biology 26, 1754–1766 (2020).
Google Scholar
-
Wright, C. K. & Wimberly, M. C. Recent land use change in the western corn belt threatens grasslands and wetlands. Proceedings of the National Academy of Sciences 110, 4134–4139 (2013).
Google Scholar
-
Tadesse, T. et al. Building the vegetation drought response index for canada (vegdri-canada) to monitor agricultural drought: First results. GIScience & Remote Sensing 54, 230–257 (2017).
Google Scholar
-
Zheng, Y. et al. Development of a phenology-based method for identifying sugarcane plantation areas in china using high-resolution satellite datasets. Remote Sensing 14, 1274 (2022).
Google Scholar
-
Pan, B. et al. High resolution distribution dataset of double-season paddy rice in china. Remote Sensing 13, 4609 (2021).
Google Scholar
-
Dong, J. et al. Early-season mapping of winter wheat in china based on landsat and sentinel images. Earth System Science Data 12, 3081–3095 (2020).
Google Scholar
-
Shen, R. et al. A 30 m resolution distribution map of maize for china based on landsat and sentinel images. Journal of Remote Sensing 2022 (2022).
-
Peng, Q. et al. CCD-Maize: A twenty-year dataset of maize distribution with high spatial resolution in China, ScienceDB, https://doi.org/10.57760/sciencedb.08490 (2023).
-
You, N. & Dong, J. Examining earliest identifiable timing of crops using all available sentinel 1/2 imagery and google earth engine. ISPRS Journal of Photogrammetry and Remote Sensing 161, 109–123 (2020).
Google Scholar
-
Chen, Y., Hou, J., Huang, C., Zhang, Y. & Li, X. Mapping maize area in heterogeneous agricultural landscape with multi-temporal sentinel-1 and sentinel-2 images based on random forest. Remote sensing 13, 2988 (2021).
Google Scholar
-
Abubakar, G. A. et al. Mapping maize fields by using multi-temporal sentinel-1a and sentinel-2a images in makarfi, northern nigeria, africa. Sustainability 12, 2539 (2020).
Google Scholar
-
Jin, Z. et al. Smallholder maize area and yield mapping at national scales with google earth engine. Remote Sensing of Environment 228, 115–128 (2019).
Google Scholar
-
Qader, S. H. et al. Exploring the use of sentinel-2 datasets and environmental variables to model wheat crop yield in smallholder arid and semi-arid farming systems. Science of the Total Environment 869, 161716 (2023).
Google Scholar
-
Zhang, L., Zhang, Z., Luo, Y., Cao, J. & Tao, F. Combining optical, fluorescence, thermal satellite, and environmental data to predict county-level maize yield in china using machine learning approaches. Remote Sensing 12, 21 (2019).
Google Scholar
-
of Statistics of China, N. B. China Statistical Yearbook (National Bureau of Statistics of China, 2017b).
-
of Statistics of China, N. B. China Statistical Yearbook (National Bureau of Statistics of China, 2018b).
-
of Statistics of China, N. B. China Statistical Yearbook (National Bureau of Statistics of China, 2019b).
-
of Statistics of China, N. B. China Statistical Yearbook (National Bureau of Statistics of China, 2020b).
-
of Statistics of China, N. B. China Statistical Yearbook (National Bureau of Statistics of China, 2021b).
-
Drusch, M. et al. Sentinel-2: Esa’s optical high-resolution mission for gmes operational services. Remote sensing of Environment 120, 25–36 (2012).
Google Scholar
-
Ding, X. et al. Prior knowledge-based deep learning method for indoor object recognition and application. Systems Science & Control Engineering 6, 249–257 (2018).
Google Scholar
-
Roychowdhury, S., Diligenti, M. & Gori, M. Image classification using deep learning and prior knowledge. In Workshops at the Thirty-Second AAAI Conference on Artificial Intelligence (2018).
-
Pettorelli, N. The normalized difference vegetation index (Oxford University Press, 2013).
-
Gurung, R. B., Breidt, F. J., Dutin, A. & Ogle, S. M. Predicting enhanced vegetation index (evi) curves for ecosystem modeling applications. Remote Sensing of Environment 113, 2186–2193 (2009).
Google Scholar
-
Reynolds, C. Input data sources, climate normals, crop models, and data extraction routines utilized by oga/ipad. United States Department of Agriculture (USDA), Foreign Agricultural Service (FAS), Office of Global Analysis (2001).
-
Oreopoulos, L., Wilson, M. J. & Várnai, T. Implementation on landsat data of a simple cloud-mask algorithm developed for modis land bands. IEEE Geoscience and Remote Sensing Letters 8, 597–601 (2011).
Google Scholar
-
Wang, H. et al. Cropformer: A new generalized deep learning classification approach for multi-scenario crop classification. Frontiers in plant science 14, 1130659 (2023).
Google Scholar
-
Medsker, L. R. & Jain, L. Recurrent neural networks. Design and Applications 5, 64–67 (2001).
-
Gruber, N. & Jockisch, A. Are gru cells more specific and lstm cells more sensitive in motive classification of text? Frontiers in artificial intelligence 3, 40 (2020).
Google Scholar
-
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
-
Wen, Y., Zhang, K., Li, Z. & Qiao, Y. A comprehensive study on center loss for deep face recognition. International Journal of Computer Vision 127, 668–683 (2019).
Google Scholar
-
Breiman, L. Random forests. Machine learning 45, 5–32 (2001).
Google Scholar
-
Gorelick, N. et al. Google earth engine: Planetary-scale geospatial analysis for everyone. Remote sensing of Environment 202, 18–27 (2017).
Google Scholar
-
You, N. et al. The 10-m crop type maps in northeast china during 2017–2019. Scientific data 8, 41 (2021).
Google Scholar
-
Han, J. et al. Prediction of winter wheat yield based on multi-source data and machine learning in china. Remote Sensing 12, 236 (2020).
Google Scholar
-
Luo, Y., Zhang, Z., Chen, Y., Li, Z. & Tao, F. Chinacropphen1km: a high-resolution crop phenological dataset for three staple crops in china during 2000–2015 based on leaf area index (lai) products. Earth System Science Data 12, 197–214 (2020).
Google Scholar
-
Li, X. Mapping annual 10-m maize cropland changes in china during 2017–2021. Figshare https://doi.org/10.6084/m9.figshare.22689751.v17 (2023).
-
Liang, J. Confusion matrix: Machine learning. POGIL Activity Clearinghouse 3 (2022).
-
Burnham, M. & Ma, Z. Climate change adaptation: factors influencing chinese smallholder farmers’ perceived self-efficacy and adaptation intent. Regional Environmental Change 17, 171–186 (2017).
Google Scholar
-
Ma, W. & Abdulai, A. The economic impacts of agricultural cooperatives on smallholder farmers in rural china. Agribusiness 33, 537–551 (2017).
Google Scholar
Acknowledgements
This study was supported by the National Natural Science Foundation of China (Grant No. 42201368), the Fundamental Research Funds for the Central Universities (310421101), and the National Natural Science Foundation of China (Grant No. 42293272).
Author information
Authors and Affiliations
Contributions
X.L., Y.Q., L.Z. and H.G. designed the study and the methodology, X.L., H.G., S.P. and Q.X. wrote the code and generated the data, X.L., Y.Q., L.Z. and J.H. analyzed the data, wrote, and edited the manuscript. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Reprints and Permissions
About this article
Cite this article
Li, X., Qu, Y., Geng, H. et al. Mapping annual 10-m maize cropland changes in China during 2017–2021.
Sci Data 10, 765 (2023). https://doi.org/10.1038/s41597-023-02665-3
-
Received: 12 May 2023
-
Accepted: 19 October 2023
-
Published: 04 November 2023
-
DOI: https://doi.org/10.1038/s41597-023-02665-3