Abstract
This dataset covers national and subnational non-pharmaceutical interventions (NPI) to combat the COVID-19 pandemic in the Americas. Prior to the development of a vaccine, NPI were governments’ primary tools to mitigate the spread of COVID-19. Variation in subnational responses to COVID-19 is high and is salient for health outcomes. This dataset captures governments’ dynamic, varied NPI to combat COVID-19 for 80% of Latin America’s population from each country’s first case through December 2021. These daily data encompass all national and subnational units in Argentina, Bolivia, Brazil, Chile, Colombia, Ecuador, Mexico, and Peru. The dataset includes individual and aggregate indices of nine NPI: school closures, work suspensions, public event cancellations, public transport suspensions, information campaigns, local travel restrictions, international travel controls, stay-at-home orders, and restrictions on the size of gatherings. We also collected data on mask mandates as a separate indicator. Local country-teams drew from multiple data sources, resulting in high-quality, reliable data. The dataset thus allows for consistent, meaningful comparisons of NPI within and across countries during the pandemic.
Background & Summary
Latin America is one of the regions most affected by the COVID-19 pandemic. Only 8% of the global population lives in Latin America, but the region accumulated 30% of total COVID-19 deaths through August 20221. There is significant variation in the distribution of cases and deaths in each country, but very few subnational or national governments used NPI effectively to combat COVID-191,2,3,4.
Data on subnational NPIs are crucial for explaining pandemic outcomes and for building knowledge on how to improve performance in future pandemics5,6,7,8,9,10,11,12,13,14,15. These data are relevant beyond pandemics, too, as federal systems of government rely on subnational units to respond to natural disasters and other crises as well as to deliver critical services under normal conditions. Similarly, the process of decentralization has allowed subnational units of unitary countries to implement their own policies, which often diverge from those of the national government. The timeliness, mix, and rigor of national and subnational NPIs in Latin America in our dataset is therefore useful for scholars and practitioners around the world, now and in the future16.
The timing, combination, and types of NPI in Latin America varied across and within the countries included in our data since the first COVID-19 case was recorded on February 25 2020, in São Paulo, Brazil17,18. Many countries had implemented at least some national restrictions by the end of March 2020, but NPI stringency and type shifted in dramatic waves over the first year of the pandemic and continues to do so in the face of outbreaks19. For example, Brazilian and Mexican national governments deferred NPI responsibility to state governments, leading to large-scale variation within each country with no central, evidence-based planning20. Understanding this variation is important, since the countries accounted for 17% of the world’s confirmed COVID-19 deaths by March 2021. It is also important for drawing lessons that will inform policy in future regional and global pandemics.
Throughout 2020 and 2021, national leaders relaxed or removed sub-national NPI to balance concerns for COVID-19 transmission with economic imperatives, and declines in mental health due to lockdowns. NPIs were also discontinued due to political, libertarian, and human rights-based controversies around their design and sometimes uneven implementation.
In Latin America, many countries also faced difficulties in collecting sufficient evidence to inform subnational policymaking. This struggle created a patchwork of NPIs within and across countries, which only rarely responded to local variation in COVID-19 cases and deaths because of minimal testing and contact tracing.
Our dataset records the timing, mix, rigor, and type of NPIs adopted at the state, province, department, and regional levels for Argentina, Bolivia, Brazil, Chile, Colombia, Ecuador, Mexico, and Peru16. The data covers 80% of Latin America’s population from the first case in each country through December 202116,21, almost two years after the first cases in each country. The data also covers different types of governance16, on a gradient of federal and unitary systems, decentralized and centralized, Left, Right, and populist governments at national and subnational levels. The daily data included in the dataset thus fill a gap in subnational, daily data with variables and methods absent from other datasets16,22.
Our dataset is distinct from others that record similar data in several ways16. First, our coding methods used large teams of native-speaking, in-country researchers to record data, rather than bots or other automated data collection16. Next our data is daily by subnational unit, not weekly or monthly, which offers unusual granularity, from the first case in each country through the end of 2021 for all eight countries and all subnational units, covering the first 22 months of the pandemic16. This timeframe is longer than other datasets on NPI to combat COVID-19. The total NPI included, the specific indicators for each, and the construction of our index also set our dataset apart from others16. In sum, our dataset is unique in its granularity, longitudinal coverage, and use of in-country research teams to code subnational data16. Our 53, 411 observations are larger than any other source for the countries in question16.
Methods
As part of the Observatory for the Containment of COVID-19 in the Americas21, we collected data on NPIs in each of the eight countries’ subnational territories, beginning with the first reported case in each country16. We focus on the state, department, or provincial level of government administration. We present data from February 25, when the first Latin American COVID-19 case was confirmed in São Paulo, Brazil, to the end of 2021, spanning the first 22 months of the pandemic in the region and the first two years for Brazil and Mexico, the region’s two largest countries16.
These data include school closures, work suspensions, public event cancellations, public transport suspensions, information campaigns, travel restrictions within states, international travel controls, stay-at-home orders, and restrictions on the size of gatherings16. We also collect and report data on mask mandates separately16. A literature review at the beginning of the pandemic guided us in the selection of these NPI, which previous scholarship identified as relevant for influencing COVID-19 cases and deaths23,24,25,26,27,28. We also relied on the Oxford COVID-19 Government Response Tracker (OxCGRT) 5.029, which recorded data on national-level policy to identify the 10 most important NPIs. Parallel data collection on NPIs to combat COVID-19 tend to include a subset of our variables30,31,32,33.
We assembled country teams of local doctors, professors, policy experts, researchers, and university students to examine which policies were in effect, when they were implemented, and whether they remained in effect each day, from the first case detected in the country. We then coded the measure’s policy implementation intensity as partial or total if it was in effect. Tables 1, 2 describe the 10 NPI indicators, their coding, and their values. We assigned the indicators several discrete levels to create possibilities for granular analyses. Scores range from 0 to 1 in discrete levels.
Our integrated research teams recorded these data by first reviewing official government websites to capture laws, decrees, and news releases announcing the implementation of each NPI. Each country-team then cross-referenced information from official government sources against news outlets’ coverage of the same laws, decrees, and announcements of NPIs. Finally, our teams performed an additional check of official government social media accounts, such as Twitter and Facebook, when government websites did not announce NPIs. Each week, we performed an internal, random check of intercoder reliability and validity. Two co-authors who were excluded from the original coding independently verified daily data for randomly selected NPI.
We then used the 9 NPI indicators (masks have a separate index) to build a daily composite index score for each national and subnational unit. Creating an index allows for comparison of governments’ overall NPI response to COVID-19 across and within countries.
Our Public Policy Adoption (PPA) Index is constructed by first summing daily scores for each NPI. Then, we account for time by multiplying the sum of NPI scores by a ratio of the days since implementation to the days since a country’s first case. We then weight the measure by estimating the mean PPA score for each administrative unit and weighing it by the population of each state, province, department, or region.
We record data on mask mandates and keep these data separately from the PPA index because the use of face masks behaves differently from the other measures16. Mask mandates or recommendations are often a feature of reopening and relaxation of restrictions on population movement. In contrast, mask mandates are designed to moderate the need for physical distancing and allow for closer contact in public and private spaces. Governments often implemented mask mandates and recommendations much later than other NPI, partially based on the WHO’s suggestions for the use of facemasks on June 5, 202033.
Public policy adoption index
The PPA summarizes governments’ actions and fosters direct comparisons of NPI both within and across countries.
The index is constructed as presented in the following Eq. (1):
Whereby:
IPPit = Public policy adoption index in country/state i at time t.
Ij = Public Policy Index j, where j goes from 1 to 10.
Dijt = Days from the first registered case until time t.
dijt = Days from the implementation of policy j until time t.
The IPPit is constructed with the sum of each of the scores from 9 of the 10 NPI, excluding mask mandates, weighted by the day of implementation relative to the first case in each country. The index gives higher scores for earlier implementation relative to the first case in the country. As such, index values rise the earlier an NPI was implemented and the longer it remains in effect.
The ratio dijt /Dijt is continuous and ranges from 0, when policy j has not yet been implemented by subnational government i at time t, to 1, for governments that implemented NPI at the same time t when the first COVID-19 case appeared in their country. We then raise the ratio dijt /Dijt to the power (1/2) to incorporate decreasing policy effectiveness following delays in NPI implementation.
In the aggregate, each subnational and national government i receives a daily score between 0 and 10, which reflects the sum of the different policy dimensions, and is then normalized to a scale of 0 to 100. The maximum index value is 100 but obtaining scores of 100 is unrealistic and, moreover, not necessarily desirable because a score of 100 would imply a complete cessation of activity in an administrative unit following the first case in the country.
We are agnostic about the relative impact of each NPI as well as governments’ rationale for their adoption and weight each NPI equally in the policy index. However, we recognize that NPI adoption and impact might not be equal across interventions and their adoption might stem from different sources. We therefore also construct daily index scores, weighted by time, for the use of facemasks and each of the remaining 9 NPI to allow for assessment of individual NPI as independent or dependent variables. Scores revert to zero when governments remove a policy mandate and return to a score between 0 and 100 as policies resume, with the count of days a policy has been in place beginning from the date of renewed implementation. Users of these data can harness them to assess individual NPIs’ impact on health outcomes, explore their determinants, and compare them to one another.
Our coding for the individual variables is based on a desire for intra- and international comparison at the subnational level and is based on different degrees of policy implementation, ranging from 0 to full. In pursuit of coding clarity and to reflect common distinctions in policy implementation, some variables have three possible values, e.g., no policy, recommended policy, and full policy implementation, whereas others have four. These variables include values for partial implementation, with scores possible between “recommended” NPI and full implementation. We recognize here as well that recommending a policy does not necessarily mean that it will be implemented at half the level of a full policy implementation, which our coding implies. Instead, our coding captures extensive subnational variation, where a state recommends a policy, and some municipalities implement it and others do not. The coding therefore reflects our judgment that a recommended policy is likely to be implemented more than no policy at all, but not as thoroughly as a mandated policy, particularly for NPI whose partial implementation is difficult to measure. This choice represents one of several limitations for creating a cross-national, subnational index that is comparable both within and across countries.
These indices and individual NPI scores translate to 60,129 observations across the 10 original indicators and the index. Additionally, we link our original data to subnational and national information on testing, cases, and deaths, for ease of analysis. These data can be linked further still to inform analysis of a wide variety of COVID-19 outcomes.
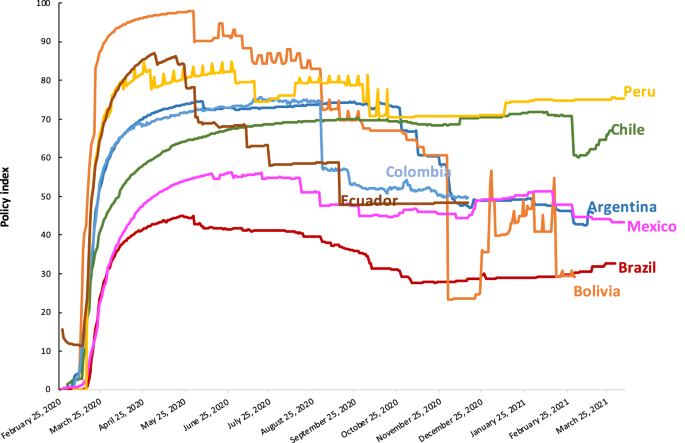
Figures 1–3 present different visualizations of the NPI policy index across countries over time, the facemask adoption index, and the policy index by individual country.

NPI to combat COVID-19 across Latin America. This Figure has been previously published in Knaul, F.M. et al. Strengthening health systems to face pandemics: subnational policy responses to COVID-19 in Latin America. Health Affairs. 41, 454–462 (2022)31.

Facemask adoption index across Latin America.

NPI to combat COVID-19 by Individual Country.
Data Records
Our dataset is available at our Harvard Dataverse under the https://doi.org/10.7910/DVN/NFSXTR The data are in.csv files, divided by country and access is free16.
Each row in the dataset corresponds to a subnational government-day, for example, “Brasil, Rio de Janeiro, March 1, 2020.” The country, subnational unit, and date are identified by the column labels “country”, “state_name”, “state_code”, and “date”. “Date is coded as MM/DD/YY across all records. The “days” column counts the days since the first COVID-19 case in each country.
The 10 NPI and the time since their implementation are listed in columns K to AD of the dataset under the variables “School_Closure”, “Days_Since_Schools_Closed”, “Workplace_Closure”, “Days_Workplace_Closure”, “Public_Events_Cancelled”, “Public_Events_Cancelled_Days”, “Public_Transit_Suspended”, “Days_Since_Transit_Suspend”, “Information_Campaign”, “Information_Campaign_Days”, “Internal_Travel_Control”, “Days_Since_Internal_Travel_Ban”, “International_Travel_Controls”, “Days_Since_International_Ban”, “Stay_at_home”, “Days_since_stay_at_home”, “Rest_on_gatherings”, “Days_rest_on_gatherings”, “Use_face_masks”, and “Days_use_face_mask”. The Public Policy Adoption index scores appear in column AF labelled “policy_index”.
Technical Validation
Each researcher from our integrated country teams coding NPI sent weekly updates to the country-team leaders. These leaders verified sources and coding choices, both for their own countries and in weekly group training sessions as we added country-teams.
Two randomly selected co-authors administered a double-blind review each week during the first four months of data collection and each month thereafter. The two co-authors reviewed randomly selected NPI scores from among each country’s subnational units that members of the country-teams coded. These co-authors then recoded data for a given government on a given day, without having seen the original NPI scores. Neither re-coder knew who coded the original data and no original coder knew which co-author would perform the review. Country teams for which we have data reported discrepancies an average of 6 times per day during the first three months of coding (across 90 daily observations: 10 indicators coded daily across a mean of 9 subnational units). This translates to a 93.7% agreement among double-blind reviewers and a Cohen’s Kappa of 0.75 (high agreement), with growing agreement as coding continued, NPIs stabilized, and were then removed altogether. Note that not all country teams were consistent in the timing or reporting of these data throughout the collection period. We report data from what we argue is a representative sample given the preponderance of data available in each period. Disagreement among coders for all country teams was most common for the “Information Campaign” variable in terms of its partial versus full implementation. Each country-team deliberated in cases of discrepancy, until consensus was reached. Following these checks, country-leaders sent monthly data to the overall project’s data managers.
Next, the project’s data managers checked for missing data, inconsistencies in coding, and mis-entered information by using STATA to perform an automated data assessment. Upon identification, the project’s data managers returned country dataset updates to country-team leaders with embedded queries. Country-teams then updated all scores and return country data to the overall project managers with any inconsistencies or errors resolved.
Project managers then combined country-level data to create a region-wide file that we used to generate monthly country and regional pages that included visualizations of each country’s NPI on each dimension. These materials were posted on the website of the University of Miami Observatory for the Containment of COVID-19 in the Americas, but without the raw data.
We validated the PPA index scores primarily by comparing them to other efforts to track subnational NPI in the Americas during the COVID-19 pandemic. Distinctions in coding methods (research assistants vs. bots, specific indicators for NPI, unit of time (daily vs. weekly or monthly), timeframe (the first year of the pandemic vs. 2020) and construction of our index all suggest that correlations with other indicators will not approach 1. Nevertheless, general assessments of stringency or lack thereof are similar.
We found that our data correlated highly with the Oxford COVID-19 Government Response Tracker16. Subnational indicators for NPI were correlated at 0.81 for countries where the Oxford Tracker included subnational data and where indicators, such as the PPA index overlapped with the similar Oxford stringency index. We also compared our index scores with Shvetsova et al.’s (2022) Protective Policy Index, which uses automated data collection to generate index scores across all global subnational units, including Latin America, through 2020. The correlation of our index with Shvetsova et al.’s is 0.86 for the country-weeks with overlap28,33. We provide a table of correlations across indices along with the data and code at the Harvard Dataverse repository16.
We used regional and national webinars in May, June, July, and December 2020 as well as February, May, and September 2021, to collect feedback from scholars and practitioners in the region and improve our data coverage. We have also published several peer-reviewed papers using these data, but the full dataset has not been publicly available1,2,3,4,16,32.
Usage Notes
We provide replication code in R and in STATA for the ease of the user; the files produce identical calculations. We used the R code for group data collection and updates. We recommend the STATA code for basic replications of our policy index and the R code for evaluating the broader coding effort, the creation of a unified database, and the collaboration across country groups. The R code may also be helpful for other groups engaged in similar research.
Code availability
The code used to replicate our index calculations and the creation of all graphics is available at the Harvard Dataverse: https://doi.org/10.7910/DVN/NFSXTR16. We provide replication code in R and in STATA for the ease of the user; the files produce identical calculations. We used the R code for group data collection and updates.
References
-
Knaul, F. M. et al. Punt politics as failure of health system stewardship: evidence from the COVID-19 pandemic response in Brazil and Mexico. Lancet Reg Health Am. 4 (2021).
-
Hummel, C. et al. Poverty, precarious work, and the COVID-19 pandemic: lessons from Bolivia. Lancet Glob Health. 9, e579–e581 (2021).
Google Scholar
-
Touchton, M. et al. A partisan pandemic: state government public health policies to combat COVID-19 in Brazil. BMJ Global Health. 6 (2021).
-
Knaul, F. et al. Not far enough: public health policies to combat COVID-19 in Mexico’s states. PLOS ONE. 16 (2021).
-
Anderson, R. M., Heesterbeek, H., Klinkenberg, D. & Hollingsworth, T. D. How will country-based mitigation measures influence the course of the COVID-19 epidemic? The Lancet. 395, 931–934 (2020).
Google Scholar
-
Haushofer, J. & Metcalf, C. J. E. Which interventions work best in a pandemic? Science. 368, 1063–1065 (2020).
Google Scholar
-
Rowan, N. J. & Moral, R. A. Disposable face masks and reusable face coverings as non-pharmaceutical interventions (NPIs) to prevent transmission of SARS-CoV-2 variants that cause coronavirus disease (COVID-19): role of new sustainable NPI design innovations and predictive mathematical modelling. Sci Total Environ. 772 (2021).
-
Kraemer, M. U. G. et al. The effect of human mobility and control measures on the COVID-19 epidemic in China. Science. 368, 493–497 (2020).
Google Scholar
-
Haug, N. et al. Ranking the effectiveness of worldwide COVID-19 government interventions. Nat Hum Behav. 4, 1303–1312 (2020).
Google Scholar
-
Vardavas, R., de Lima, P. N. & Baker, L. Modeling COVID-19 nonpharmaceutical interventions: exploring periodic NPI strategies. Preprint at https://www.medrxiv.org/content/10.1101/2021.02.28.21252642v2 (2021).
-
Rocha, R. et al. Effect of socioeconomic inequalities and vulnerabilities on health-system preparedness and response to COVID-19 in Brazil: a comprehensive analysis. Lancet Glob Health. 9, e782–e792 (2021).
Google Scholar
-
Soltesz, K. et al. The effect of interventions on COVID-19. Nature. 588, e26–e28 (2020).
Google Scholar
-
Flaxman, S. et al. Estimating the effects of non-pharmaceutical interventions on COVID-19 in Europe. Nature. 584, 257–261 (2020).
Google Scholar
-
McCoy, L. G. et al. Characterizing early Canadian federal, provincial, territorial and municipal nonpharmaceutical interventions in response to COVID-19: a descriptive analysis. CMAJ Open. 8, e545–e553 (2020).
Google Scholar
-
Davies, N. G., Kucharski, A. J., Eggo, R. M., Gimma, A. & Edmunds, W. J. Effects of non-pharmaceutical interventions on COVID-19 cases, deaths and demand for hospital services in the UK: a modelling study. Lancet Public Health. 5, e375–e385 (2020).
Google Scholar
-
Touchton, M. Non-Pharmaceutical Interventions to Combat COVID-19 in the Americas: Subnational, Daily. Data. Harvard Dataverse https://doi.org/10.7910/DVN/NFSXTR (2022).
-
De Souza, W. M. et al. Epidemiological and clinical characteristics of the COVID-19 epidemic in Brazil. Nat Hum Behav. 4, 856–865 (2020).
Google Scholar
-
Rodriguez-Morales, A. J. et al. COVID-19 in Latin America: the implications of the first confirmed case in Brazil. Travel Med Infect Dis. 35 (2020).
-
Garcia, P. J. et al. COVID-19 response in Latin America. Am J Trop Med Hyg. 103, 1765–1772 (2020).
Google Scholar
-
Burki, T. COVID-19 in Latin America. Lancet Infect Dis. 20, 547–548 (2020).
Google Scholar
-
University of Miami. COVID-19 Observatory. Observatory for the Containment of COVID-19 in the Americas http://observcovid.miami.edu/ (2022).
-
Cowling, B. J. et al. Impact assessment of non-pharmaceutical interventions against coronavirus disease 2019 and influenza in Hong Kong: an observational study. Lancet Public Health 5, e279–e288 (2020).
Google Scholar
-
Hao, X. et al. Reconstruction of the full transmission dynamics of COVID-19 in Wuhan. Nature. 584, 420–424 (2020).
Google Scholar
-
Lai, S. et al. Effect of non-pharmaceutical interventions to contain COVID-19 in China. Nature. 585, 410–413 (2020).
Google Scholar
-
Lavezzo, E. et al. Suppression of a SARS-CoV-2 outbreak in the Italian municipality of Vo’. Nature. 584, 425–429 (2020).
Google Scholar
-
Pan, A. et al. Association of public health interventions with the epidemiology of the COVID-19 outbreak in Wuhan, China. JAMA. 323, 1915–1923 (2020).
Google Scholar
-
Ruktanonchai, N. W. et al. Assessing the impact of coordinated COVID-19 exit strategies across Europe. Science. 369, 1465–1470 (2020).
Google Scholar
-
Hale, T. et al. Variation in government responses to COVID-19. BSG-WP-2020/032 Version 10.0. Blavatnik School of Government Working Paper. https://www.bsg.ox.ac.uk/sites/default/files/2020-12/BSG-WP-2020-032-v10.pdf (2020).
-
Walker, P. G. et al. The impact of COVID-19 and strategies for mitigation and suppression in low- and middle-income countries. Science. 369, 413–422 (2020).
Google Scholar
-
Li, Y. et al. Effectiveness of localized lockdowns in the COVID-19 pandemic. Am J Epidemiol. 191, 812–824 (2022).
Google Scholar
-
Knaul, F. M. et al. Strengthening health systems to face pandemics: subnational policy responses to COVID-19 in Latin America. Health Affairs. 41, 454–462 (2022).
Google Scholar
-
Shvetsova, O. et al. Protective Policy Index (PPI) global dataset of origins and stringency of COVID 19 mitigation policies. Sci Data. 9, 319 (2022).
Google Scholar
-
World Health Organization. Mask use in the context of COVID-19: interim guidance. World Health Organization https://apps.who.int/iris/bitstream/handle/10665/337199/WHO-2019-nCov-IPC_Masks-2020.5-eng.pdf?sequence=1&isAllowed=y (2020).
Acknowledgements
The data collection for this article was conducted as part of the work of the Observatory for the Containment of COVID-19 in the Americas, which includes researchers and students throughout the region. The authors are grateful to all Observatory members for their inputs and participation in the work of the research hub. The authors also thank Alessandra Maggioni and Renu Sara Nargund from the Institute for Advanced Study of the Americas and Klaudia Angélica Arizmendi Barrera for excellent research assistance. Several contributors to the Observatory merit special recognition: Lenny Martínez, Salvador Acevedo Gómez, Raymond Balise, Miguel Betancourt Cravioto, Layla Bouzoubaa, Karen Jane Burke, Alberto Cairo, Carmen Elena Castañeda Farill, Fernanda Da Silva, Daniel Alberto Díaz Martínez, Javier Dorantes Aguilar, Ariel García Terrón, L. Lizette González Gómez, Kim Grinfeder, Héctor Hernández Llamas, Sallie Hughes, Karen L. Luján López, Víctor Arturo Matamoros Gómez, Cesar Arturo Méndez Lizárraga, Gerardo Pérez Castillo, Julio Rosado Bautista.
Author information
Authors and Affiliations
Contributions
Each author’s contribution to the work should be described briefly, on a separate line, in the Author Contributions section. Michael Touchton: Co-Founder of the University of Miami Observatory for the Containment of Covid-19 in the Americas. Leader of Brazil team. Drafted data report. Co-led the development of indicators, methods, and general data collection. Felicia Marie Knaul: Co-Founder of the University of Miami Observatory for the Containment of Covid-19 in the Americas. Co-Led development of indicators and methods. Wrote data descriptions and co-led papers on Mexico, Brazil, and regional analyses. Co-led Mexico research teams and identified affiliated universities and research team members. Hector Arreola-Ornelas: Led all data management; Co-led Mexico country-team; Contributed to development of indicators. Thalia Porteny: contributed to data conceptualization, analysis, Mexican data collection. Oscar Mendez Carniado: Assisted with data management for all countries, contributed to Mexican data collection. Marco Antonio Faganello: Assisted with Brazilian data collection. Calla Hummel: Led Bolivia country-team. Silvia Otero-Bahamon: Led Colombia country-team. Jorge Insua: Led Argentina country-team Pedro Pérez-Cruz: Co-led Chile country-team Eduardo Undurraga: Co-led Chile country-team. Fausto Patino: Led Ecuador country-team. V. Ximena Velasco Guachalla: Contributed to Bolivian data. Jami Nelson-Nuñez: Contributed to Bolivian data. Carew Boulding: Contributed to Bolivian data. Renzo Calderon-Anyosa: Managed Peruvian data collection, contributed to visualization material. Patricia J Garcia: Led Peru country-team. Valentina Vargas Enciso: Contributed to project management and manuscript preparation for submission.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Reprints and Permissions
About this article
Cite this article
Touchton, M., Knaul, F.M., Arreola-Ornelas, H. et al. Non-pharmaceutical interventions to combat COVID-19 in the Americas described through daily sub-national data.
Sci Data 10, 734 (2023). https://doi.org/10.1038/s41597-023-02638-6
-
Received: 21 January 2023
-
Accepted: 12 October 2023
-
Published: 21 October 2023
-
DOI: https://doi.org/10.1038/s41597-023-02638-6