Abstract
Affectivism is a research trend dedicated to the study of emotions and their role in cognition and human behavior. Affectivism both complements and competes with cognitivism, which typically neglects affect in explaining behavior. By the nature of their subject, both affectivism and cognitivism constitute fertile grounds for studying the confluence of conceptual knowledge from diverse disciplines, which is often credited with major breakthroughs and is known as convergence science. Analyzing over half a million relevant publications from PubMed, selected according to psychologist chosen MeSH terms, we find that affectivism yields higher impact than cognitivism, as measured through normalized citations. Importantly, this higher impact is strongly associated with higher multidisciplinarity in the citations of affectivism publications but lower multidisciplinarity in the papers themselves. Hence, the case of affectivism suggests that research content of low topical diversity but broad value can generate strong and wide-ranging scholarly impact, feeding downstream convergence.
Introduction
For the first half of the 20th century, behaviorism held strong in psychological sciences as the preferred method of understanding human behaviors. Per behaviorism, behaviors are either innate or formed through conditioning, which is interaction with the environment1. This viewpoint carries the following important implication: behavior can be studied through external observations alone; cognition and emotions are considered subjective and thus, not reliable explanatory variables of behavior.
By the 1950s, the cognitive sciences began emerging as a response to behaviorism’s limitations2. Cognitivism argued that cognitive representations and information processing could be used to explain behavior3, while still typically neglecting emotion and other affective processes. Cognitivism was central to psychological theory and practice in the second half of the 20th century. Because cognitivism was, early on, linked to brain science—a melting pot of various scientific fields4,5,6—and to other disciplines such as philosophy and linguistics, cognitivism could arguably be considered as a convergence science paradigm7.
Since the later part of the 20th century, complementing the cognitive sciences, the field of affective sciences emerged precisely to understand those phenomena that were typically neglected by the cognitive sciences: emotions and other affective processes8. It has recently been proposed that, as a result of the emergence of affective sciences with foundations in the cognitive sciences, the framework of affectivism now brings into the fold emotions, feelings, and other affective processes to explain both cognition and behavior. In a recent consensus paper, over 60 scientists from various disciplines suggested that affectivism is not only on the rise but is also characterized by increasing multi-disciplinary interactions9. Per this view, affectivism is cast as a natural experiment in convergence science. The capacity of convergence science to address grand research challenges is widely acknowledged10, but its inner workings are not yet completely understood. This motivates a deeper study of affectivism and the affective sciences vis-à-vis cognitivism and the cognitive sciences to reveal the role of convergent processes in the development of these two fields, and ultimately the interdisciplinary understanding of mind, brain, and behavior.
A key issue that drives our investigation is the nature of convergence in affectivism vs. cognitivism and how it is associated to the impact of these two schools. In this respect, our study could be viewed as an effort to put to test some of the ideas proposed by the recent consensus paper on the rise of affectivism9. Thematically, we differentiate between Affective papers (i.e., those papers that focus on topics that are typical of the affective sciences), Cognitive papers (i.e., those papers that focus on topics that are typical of the cognitive sciences), and Mixed papers that seem to draw from both affective and cognitive sciences. The Affective and Mixed categories fall under the affectivism trend, while the Cognitive category falls under the cognitivism trend. Methodologically, we differentiate between the convergent content of a paper vs. the convergent interest this paper generates in the literature after it has been published. This analytical approach is meant to address a profound and heretofore open research question regarding convergence’s generative mechanism:
Because convergence science is associated with research advances10, investigating the generative mechanisms of convergence is akin to looking for the mother lode.
Methods
We seek to understand how thematic diversity (aka multidisciplinary content), which is a fundamental measure of convergence science, maps onto research outcomes in affectivism and cognitivism. We quantify such outcomes via citation impact, employing normalization methods consistent with best practices11. To ameliorate confounding effects and increase trust in any association between citation impact and thematic diversity, we seek to include in our models well-known citation controls. In this direction, Tahamtan & Bornmann proposed a set of article-level factors that can influence citing behavior12. These factors include in order of importance:
-
Topical composition of article: The topical composition of an article is not only a broadly recognized factor of citation impact, but also a fundamental element of convergence science analysis. In every science of science investigation we performed thus far, the topical composition of articles emerged as a strong predictor of citation impact. These investigations included analysis of the genomics13 and brain science4 literature. As described in subsequent sections, we account for the topical composition of an article through its Medical Subject Headings (MeSH) keywords.
-
Authorship of article: We account for author factors by including into our model the author count A(pi) for each publication pi. It has been reported in the literature that the number of authors in papers positively correlates with the citations these papers receive12. We had the opportunity to confirm this relationship in our prior research, when investigating the genomics literature13. The said effect is partly related to the visibility of the research in the scientific community, which grows in proportion to each author being an advocate of the published work.
-
Publishing venue of article: Our accounting of the article’s topical composition also serves as a proxy for the disciplinary orientation of the publishing journal. We avoid incorporating additional journal-level metrics, like the journal’s impact factor, because of dramatic changes in the ecosystem of publishing venues in recent years, which complicate consideration of such metrics. These changes include the meteoric rise of articles in open access journals and arXiv, two categories for whom impact factor considerations are confounded by open access status and publication fee/no fee requirements14,15.
Next, we describe the construction of the dataset and the computation of the model’s key predictors and response variable.
Bibliographic data collection and annotation
This study was not preregistered. PubMed served as our preferred bibliographic database for two reasons: First, both affective and cognitive scholarship are largely represented in PubMed, ensuring good coverage. Second, bibliographic records in PubMed are authoritatively annotated with MeSH keywords by the National Library of Medicine16. MeSH is a controlled and hierarchically-organized vocabulary with nearly orthogonal definitions17. Thus, it leaves little room for ambiguity in selecting search keywords. Accordingly, PubMed has both the items and ground-truth needed to power the present study.
Two of the co-authors, experts from the psychological sciences, agreed on a set of MeSH terms that comprehensively describe affective and cognitive research topics (Table 1). The said experts used as guidance for the selection of said terms the distinctions provided elsewhere9 between what traditionally constitutes a topic associated with cognitive vs. affective sciences. For instance, typical topics associated with cognitive sciences include attention, decision-making, executive functioning, language learning, memory, perception, and reasoning, while typical topics associated with affective sciences include emotion, empathy, feeling, mood, motivation, preferences, stress, and well-being.
Using the selected MeSH terms, we searched PubMed, which had 34,944,599 records at the time of our inquiry in May 2023. The said search yielded in total 649,033 publications; out of these 314,665 were classified as Affective and 314,968 were classified as Cognitive publications, because they were annotated with at least one of the MeSH terms shown in Table 1 attributed to topics that are particularly typical of the cognitive and affective sciences, respectively. The remaining 19,400 publications were classified as Mixed, because they were annotated with at least one MeSH term from each of the Affective and Cognitive categories. Such co-occurrence of affective and cognitive terms is suggestive of non-independent treatment of affective and cognitive topics. Hence, Mixed publications fall in line with the principles espoused by affectivism, where any complete model of what is typically considered a cognitive topic (e.g., attention, memory, or decision-making) should include affective processes.
Each PubMed publication is annotated with both major and non-major topic terms, with the major topic terms indicating primary themes in the paper. We used only major topic terms to reduce noise levels. Furthermore, and consistent with other reports in the science convergence literature4,5, we proceeded into thematic consolidation. In more detail, the MeSH tree ontology16 is organized around 16 major branches: [A] Anatomy; [B] Organisms; [C] Diseases; [D] Chemicals and Drugs; [E] Techniques and Equipment; [F] Psychiatry and Psychology; [G] Phenomena and Processes; [H] Disciplines and Occupations; [I] Anthropology, Education, Sociology, and Social Phenomena; [J] Technology; [K] Humanities; [L] Information Science; [M] Named Groups; [N] Health Care; [V] Publication Characteristics; and [Z] Geographicals. The first 14 branches hold terms relevant to our study. We consolidated these 14 branches into five subject areas (SA):
-
SA1 ≡ Biological Sciences corresponding to [A, B, G]
-
SA2 ≡ Psychological Sciences corresponding to [F]
-
SA3 ≡ Medical Sciences corresponding to [C, N]
-
SA4 ≡ Technical Methods corresponding to [D, E, J, L]
-
SA5 ≡ Humanities corresponding to [H, I, K, M]
Next, we will describe how we used this five-class thematic annotation scheme to represent the topical nature and estimate the degree of thematic confluence (aka convergence science) in each publication and its citations.
Key predictors: multidisciplinary content and appeal of publications
The thematic content of each publication pi is represented by a five element vector (overrightarrow {{mathscr{T}}}({p}_{i})={{e}_{1},{e}_{2},{e}_{3},{e}_{4},{e}_{5}}), where e1, e2, e3, e4, e5 indicate the number of subject area terms from SA1, SA2, SA3, SA4, SA5, respectively, associated with this paper. For instance, a hypothetical paper ph with thematic vector (overrightarrow {{mathscr{T}}}({p}_{h})={2,1,0,0,0}) indicates that its PubMed MeSH annotation features two major topic terms falling under SA1 and one under SA2. This suggests that the said paper’s content is multidisciplinary, featuring a mixture of biological and psychological knowledge.
The question now arising is how can we quantify thematic diversity out of such thematic representation? Two types of diversity indices are common in the literature—the Blau index and the Stirling index18,19,20. Diversity indices typically capture both categorical variety and categorical distances. Accordingly, they differ in the way they derive categorical variety and the way they compute categorical distances. Typical derivation methods include repeated sampling and combinations.
Our diversity index derives categorical diversity but leaves out computation of categorical distances. This is because the labeling of publications in our dataset is based on MeSH, which is a hierarchical ontology with well-defined distinctions between categories. Hence, there is little need to define categorical distances. In more detail, our diversity index computes categorical diversity through a combinatorial measure5. For each paper pi, we apply the outer tensor product (overrightarrow {{mathscr{T}}}({p}_{i})bigotimes overrightarrow {{mathscr{T}}}({p}_{i})) to represent all pair-wise co-occurrences in a matrix D(pi). The order of any vector elements ei and ek in these pairs plays no meaningful role. Hence, we only keep the co-occurrence matrix’s upper triangular portion: Du(pi) = triu(D(pi)). We normalize the sum of the elements of Du(pi) to unity, so that each ({{{bf{D}}}}_{N}^{u}({p}_{i})) contributes equally to means computed over selected publication groups. Normalization is implemented through Eq. (1), where the notation ∥ ⋯ ∥ indicates summation of all matrix elements.
Since the off-diagonal elements of ({{{bf{D}}}}_{N}^{u}({p}_{i})) represent cross-thematic combinations, their relative weight given by (D({p}_{i})=1-,{{mbox{tr}}},({{{bf{D}}}}_{N}^{u}({p}_{i}))) can be used as a measure of thematic diversity or multidisciplinarity. In essence, D(pi) quantifies the probability of two randomly-selected elements of the thematic vector belonging in different categories.
When it comes to the citations paper pi has received, each of these citations cij features its own thematic diversity vector (overrightarrow {{mathscr{T}}}({c}_{ij})) and diversity index D(cij). We compute the mean thematic diversity ({bar{D}}_{c}({p}_{i})) of all citations cij, j = 1…m associated with publication pi through Eq. (2). One can view ({bar{D}}_{c}({p}_{i})) as a measure of multidisciplinary appeal of publication pi.
Response variable: citation impact
We used the iCite tool21 to collect reference and citation data for the publications in our dataset. iCite draws citation numbers from the PubMed database. Unlike PubMed, iCite provides for each publication detailed records of all the papers that cite this publication. In our case, such information is necessary for tracing the thematic composition of the citing papers. We found, however, that out of the 649,033 publications in the dataset 39,972 featured zero references and/or citations—a 6.15% of the whole. We chose to keep such uncited articles in our analysis for their contribution to bibliographic patterns as evidenced in recent bibliometric work22.
The dataset’s papers were published over the 73-year period between January 1950 and December 2022. Naturally, the longer a publication exists, the more opportunity it has to receive citations. This creates a temporal bias in citation records, which in our case is significant, because of our dataset’s long time span. To account for this bias, we normalize citations following the standard methodology reported in other science of science research4. Specifically, the distribution of citations for papers published the same year t has an approximately log-normal form23. Hence, we use the properties of the log-normal transformation to standardize the distribution of citations by applying the formula shown in Eq. (3). Given that c(pi) stands for the citations of a given publication pi, we use ({c}^{{prime} }({p}_{i})=c({p}_{i})+1) to avoid the singularity of (ln 0) associated with uncited publications – a standard method that does not affect results4. Furthermore, (overline{ln {c}_{t}^{{prime} }}) represents the mean of the log of citations calculated across all publications from the same year t as publication pi, and ({s}_{t}[ln {c}_{t}^{{prime} }]) represents the standard deviation of (ln {c}_{t}^{{prime} }) calculated for the same publication cohort.
According to Eq. (3), CN(pi) is a standard log-transformed quantity that is approximately normally distributed, bearing the advantageous properties of z-score (i.e., mean = 0 and standard deviation = 1). In this way, citation impact is measured relative to the within-cohort baseline, such that values with CN(pi) > 0 are rated above average relative to other research published at approximately the same time. It has been shown in literature that properly normalized citations assume a universal form23. Indeed, when we apply Eq. (3) to our citation data, the citation distributions per production year assume the standard normal form (Supplementary Fig. S1).
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Results
Descriptive statistics
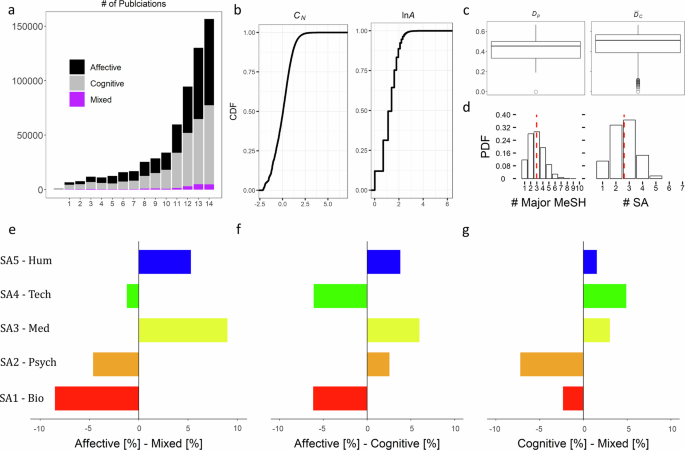
The dataset of this study contains bibliographic records for np = 649, 033 publications. In this set, ({n}_{{p}_{a}}=314,665) publications have been classified as Affective, ({n}_{{p}_{c}}=314,968) publications as Cognitive, and ({n}_{{p}_{m}}=19,400) as Mixed. Figure 1A shows the evolution of publication production over time. The Affective and Cognitive groups appear to follow similar patterns and also feature similar volumes. The Mixed group is the smallest among the three and has grown into non-trivial numbers relatively recently.

a Histogram of the number of Affective (({n}_{{p}_{a}}=314,665)), Cognitive (({n}_{{p}_{c}}=314,968)), and Mixed (({n}_{{p}_{m}}=19,400)) publications per epoch; epochs represent non-overlapping 5-year intervals, spanning from 1 (corresponding to 1950) to 14; just the last epoch spans eight years, from 2015 to 2022. b Cumulative distribution function (CDF) of the normalized citations and the log of the number of authors per article. c Boxplots indicating the inter-quartile range of Dp and ({bar{D}}_{C}) for np = 649, 033 publications. d Probability density function (PDF) of the major topic MeSH terms and their subject area aggregates (SA). e Percent difference of SA occurrences between the Affective and Mixed groups. f Percent difference of SA occurrences between the Affective and Cognitive groups. g Percent difference of SA occurrences between the Cognitive and Mixed groups. Note that SA1 ≡ Biological Sciences, SA2 ≡ Psychological Sciences, SA3 ≡ Medical Sciences, SA4 ≡ Technical Methods, and SA5 ≡ Humanities.
Figure 1B shows the cumulative distribution function (CDF) calculated for both the normalized citations (CN) and the number of authors per publication (A). The descriptive statistics of the normalized citation count per publication CN(pi) are ({bar{C}}_{N}pm {s}_{{C}_{N}}=0.00pm 1.00). This result indicates that the normalization process was carried out correctly, as it rendered CN to be a standard normal distribution with mean zero and standard deviation one – see also Supplementary Fig. S1 for year by year validation of citation normalization. The number of authors per publication A(pi) is a right skewed distribution with median (tilde{A}=4), interquartile range AIQR = [2, 5], and maximum value Amax = 460. Since the variation in A(pi) across various domains of scientific research follows a log-normal distribution24, we comply with normality assumptions by applying the logarithmic transformation (ln A). The descriptive statistics of the transformed author distribution are (overline{ln A}pm {s}_{ln A}=1.22pm 0.67).
Figure 1 C juxtaposes the distribution of the thematic diversity of publication pi (denoted by Dp) with the distribution of the average thematic diversity of those papers that cited pi (denoted by ({bar{D}}_{C})). The descriptive statistics of the thematic diversity per publication are ({D}_{p}pm {s}_{{D}_{p}}=0.39pm 0.17). The descriptive statistics of the mean thematic diversity of citations per publication are ({bar{bar{D}}}_{c}pm {s}_{{bar{D}}_{c}}=0.43pm 0.21). Thus, the thematic diversity of citing papers tends to be broader than the cited papers. Models will show this effect to be more strongly associated with the Mixed and Affective groups (Publication Type Model section).
As we detailed in the Key Predictors section, the source data for computing the thematic diversity of publications in our dataset are the major topic MeSH terms associated with these publications. Figure 1D shows the distribution of the number of MeSH terms per publication vs. the distribution of the number of their subject area aggregates; the corresponding descriptive statistics are 2.91 ± 1.15 vs. 2.53 ± 0.78. It is evident that subject area aggregation curtails the excessive right skeweness found in the original major MeSH term cardinality distribution.
Figures 1E–G visualize the relative thematic diversity of Affective vs. Mixed, Affective vs. Cognitive, and Cognitive vs. Mixed research, respectively. We report the relative differences by calculating the percent difference in terms of subject area occurrences between the applicable groups in each case. We observe that with respect to the Cognitive and Affective literature, the Mixed literature has richer biological (SA1) and psychological (SA2) content, while lags in nearly all other subject areas (Fig. 1E and G). In doing so, the Mixed literature group brings together the biological (SA1) content advantage of the Cognitive group with the psychological (SA2) content advantage of the Affective group (Fig. 1F). This fusion advantage of the two core themes may be narrow in scope but consequential for the Mixed literature, as the citation impact model in the next section indicates.
Citation impact model
As we observed in the Descriptive Statistics section, the Affective and Cognitive groups appear to have remarkably similar productivity levels in terms of publication volumes, while the Mixed group is a more recent development. Questions, however, remain about other aspects of research productivity for the studied scholarly system. Here we seek to identify factors that correlate with the normalized citation impact of a given publication, CN(pi). To this end, we constructed a multiple linear regression model featuring predictors relevant to our research question, as well as control variables aiming to ameliorate confounding effects:
The unit of analysis is a single publication pi. The first row of Eq. (4) lists the key predictors TA(pi), TC(pi), Dp(pi), and ({bar{D}}_{c}({p}_{i})). The dummy variables TA(pi) and TC(pi) represent the Affective and Cognitive publication groups, respectively; the Mixed publication group serves as the reference level. The variable Dp(pi) represents the thematic diversity of pi, which is akin to its multidisciplinary content. The variable ({bar{D}}_{c}({p}_{i})) represents the mean thematic diversity of the papers that cited pi, which is akin to its multidisciplinary appeal. The second row of Eq. (4) lists the control variables A(pi), FSA1(pi), FSA2(pi), FSA3(pi), FSA4(pi), and FSA5(pi). The variable A(pi) represents the number of authors per publication. As this control variable is heavily right-skewed, we apply logarithmic transformation. FSA1(pi), FSA2(pi), FSA3(pi), FSA4(pi), and FSA5(pi) are binary control variables indicating for publication pi the presence ( = 1) or absence ( = 0) of major MeSH terms associated with subject areas SA1, SA2, SA3, SA4, and SA5, respectively.
Table 2 shows the full set of parameter estimates specified in Eq. (4). Figure 2A provides a visual representation of the marginal effects associated with shifts in publication categorical levels, with all other covariates held at their mean values. Results indicate that Affective publications have lower citation impact than Mixed publications, corresponding to roughly 100*( −0.045) = −4.5% difference in nominal citations, c(pi). Cognitive publications have even lower citation impact than Mixed publications, corresponding to roughly 100*( −0.065) = −6.5% difference in nominal citations, c(pi). And consistent with prior studies4, the number of authors positively correlates with citation impact, such that a 100% increase in A(pi) correlates to a 100*(0.223) = 22.3% increase in c(pi). Interestingly, we identify a negative correlation between CN(pi) and Dp(pi), meaning that the higher the thematic diversity of a publication the lower its citation impact. Thus, rich multidisciplinary content appears to be unhelpful to a publication’s impact. By contrast, the higher the mean thematic diversity of papers citing pi, the higher the citation impact of pi (Fig. 2B). Consequently, impact seems to be helped by the publication’s multidisciplinary appeal. Regarding the controlling role of topical content, as manifested by subject area keywords, the model results in Table 2 indicate that biological (SA1) content is associated with higher citation impact, psychological (SA2) content makes no difference, while medical (SA3), technical (SA4), and humanities (SA5) content is associated with lower citation impact. Since the thematic epicenter of Cognitive, Affective, and Mixed publications is psycho-biology (SA1 + SA2), thematic diversity is stemming from SA3, SA4, and SA5. Thus, the negative coefficients of FSA3, FSA4, and FSA5 are consistent with the negative coefficient of Dp(pi), manifesting the overall suppressing effect of thematic diversity on citation impact. At the same time, the citation advantage associated with SA1 content brings to mind the Mixed group’s strong incorporation of biological (SA1) into psychological (SA2) knowledge (Fig. 1E and G), which may partly explain the said group’s superior impact.
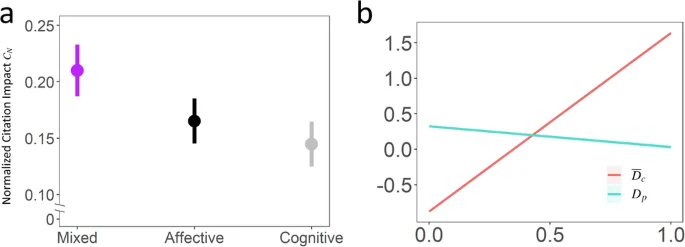
a Marginal means with 95% confidence intervals for Mixed (({n}_{{p}_{m}}=19,400)), Affective (({n}_{{p}_{a}}=314,665)), and Cognitive (({n}_{{p}_{c}}=314,968)) publications. The plot shows that Mixed publications (magenta) are more impactful than Affective publications (black), which in turn are more impactful than Cognitive publications (grey). b The red line depicting ({bar{D}}_{c}) is another key result of the citation impact model, demonstrating that the more diverse the citations of a publication are, the higher the impact of this publication will be.
Publication type model
To identify any significant structural differences among the Mixed, Affective, and Cognitive literature groups, we operationalized a multinomial regression model, specified as:
The response variable is the odds P(T(pi)) of publication pi being an Affective or Cognitive type vs. Mixed type. As in the first model: a) the predictor Dp(pi) ∈ [0, 1] represents the thematic diversity of a given publication pi, that is, pi’s degree of multidisciplinarity; b) the predictor ({bar{D}}_{c}({p}_{i})in [0,1]) represents the mean thematic diversity of the papers citing pi, that is, pi’s multidisciplinary appeal.
Table 3 lists the full set of parameter estimates specified in Eq. (5), when the response variable is the probability of being Affective or Cognitive publication. Results indicate that papers with higher thematic diversity are more likely to be of Cognitive or Affective type rather than Mixed type. The most consequential distinction among the three groups, however, lies in the SA diversity of the downstream citing research. The higher the thematic diversity of citing research, the more likely the research is of Mixed type, which is congruent with the results of the citation impact model in Eq. (4). Nevertheless, as evidenced by the corresponding regression coefficients, lower levels of thematic diversity in citations are more pronounced in Cognitive (({bar{D}}_{c}({p}_{i})=-1.264)) rather than Affective publications (({bar{D}}_{c}({p}_{i})=-0.945)). Altogether, there is a rank order of multidisciplinary appeal, with Mixed publications at the top, Affective publications next, and Cognitive publications at the bottom.
Behind the numbers
Mixed literature group
To give a tangible sense of the modeling results, we visit a few characteristic examples from our dataset. From the Mixed group, a representative publication is “Effects of Stress Throughout the Lifespan on the Brain Behaviour and Cognition”, authored by Lupien et al. and published in Nature Reviews Neuroscience in 200925. As of April 29, 2023, this paper had 3299 citations per iCite and a normalized citation score CN = 3.69 per Eq. (3). The paper is a treatise on the origins and effects of chronic stress. It examines how sustained exposure to stress hormones affects the brain, behavior, and cognition. As the major MeSH terms include among others Behavior [D001519], Stress, Psychological [D013315] and Cognition [D003071], it is clear per Table 1 that this is indeed a Mixed publication. Furthermore, the publication’s content features a measure of convergence, drawing upon two subject areas: a) Biological Sciences (SA1), owing to its hypothalamus-pituitary-adrenal content, that is, a key brain system underlying the generation of stress responses. b) Psychological Sciences (SA2), owing to its content on the effects of stress on behavior and cognition. Indeed, the SA vector for this publication is (overrightarrow {{mathscr{T}}}(p)={1,1,0,0,0}) and thus its thematic diversity stands at Dp = 0.33 per Eq. (1). This is a relatively low thematic diversity, focused on the core areas of biology and psychology. The mean thematic diversity of the paper’s citations, however, stands at ({bar{D}}_{c}=0.64) per Eq. (2). This is twice the size of Dp.
The typical pattern of Mixed publications is that they combine features from the Affective and Cognitive groups, delivering outstanding impact and featuring citations with high thematic diversity. To substantiate the last point, we will comment on a few representative articles that cite Lupien’s paper. First, we visit the citation by Herman et al. titled “Regulation of the Hypothalamic-Pituitary-Adrenocortical Stress Response”26. The paper was published in 2016 in Comprehensive Physiology and examines the role of previous stress history and current environmental demands on the regulation of the hypothalamo-pituitary-adrenocortical (HPA) axis. This HPA axis is key to stress adaptation and thus plays a major role in the onset or avoidance of chronic stress. Herman brings up Lupien’s paper with respect to maladaptive effects on HPA during the stress hyporesponsive period (SHRP) early in life. As evidenced by its major topic MeSH terms, the said citation covers the SA1 ≡ Biological Sciences area, owing to its focus on the neural mechanisms associated with stress regulating hormones.
Second, we visit the citation by Epel et al. titled “More Than a Feeling: A Unified View of Stress Measurement for Population Science”27. The paper was published in 2018 in Frontiers in Neuroendoecrinology and proposes a stress model that incorporates epidemiological, affective, and psychophysiological perspectives. Epel brings up Lupien’s paper in the context of developmental factors for which their stress model must account. As evidenced by its major topic MeSH terms, the said citation covers three subject areas: SA1 ≡ Biological Sciences, owing to its treatment of physiological regulation as a key stress modeling factor. SA2 ≡ Psychological Sciences, owing to its treatment of emotions as another key stress modeling factor. SA4 ≡ Technical Methods, owing to its model construction content.
Third, we visit the citation by Chanda and Levitin titled “The Neurochemistry of Music”28. The paper was published in 2013 in Trends in Cognitive Sciences and examines the effect of music in pleasure, stress, immunity, and social affiliation, effected through neurochemical changes. Chanda and Levitin bring up Lupien’s paper when they lay out the neurotoxic and other serious effects of chronic stress, for which Lupien’s work comprehensively accounts. As evidenced by its major topic MeSH terms, the said citation covers two subject areas: SA1 ≡ Biological Sciences, owing to its examination of music effects on the hypothalamic-pituitary-adrenal (HPA) axis and other brain systems. SA5 ≡ Humanities, owing to its analysis of music.
Altogether, the thematic diversity of the representative citations we discussed draws from a set that includes nearly all subject areas, that is, SA1, SA2, SA4, and SA5. Hence, the citations of Lupien’s paper have thematic diversity that far exceeds the paper’s own thematic diversity, which is limited to just SA1 ≡ Biological Sciences and SA2 ≡ Psychological Sciences.
Affective literature group
From the Affective group, a representative publication is the “Netherlands Study of Depression and Anxiety (NESDA)”, which was published in the International Journal in Psychiatric Research in 200829. As of April 29, 2023, this paper had 733 citations per iCite and a normalized citation score CN = 2.81 per Eq. (3). The paper describes a naturalistic study involving the longitudinal collection of multimodal participant data. The study’s aim was to understand the evolution and consequences of depressive and anxiety disorders. Accordingly, the publication’s content is mono-thematic, situated in SA2 ≡ Psychological Sciences. Indeed, the SA vector for this publication is (overrightarrow {{mathscr{T}}}(p)={0,1,0,0,0}) and thus, its thematic diversity stands at Dp = 0 per Eq. (1). In contradistinction, the mean thematic diversity of the paper’s citations stands at ({bar{D}}_{c}=0.62) per Eq. (2) and is on par with the Mixed group example we gave in the previous section.
Combing the data, we found that firstly Mixed and secondly Affective publications, even with mono-thematic psychological pedigree (like NESDA), attain strong impact rooted in broad appeal – something that is in agreement with the modeling results (Tables 2 and 3). We argue that this is due to two reasons: First, affective conditions, like anxiety, are widespread and thus of broad interest. Second, affective conditions are complex and poorly understood, forcing researchers to collect multimodal data (e.g., psychological, physiological, and other channels), in the hope of acquiring much needed insights. This rich multi-channel information can feed studies in more than one disciplines. To substantiate these points, we will comment on three thematically dissimilar articles that cite the NESDA paper.
First, we visit the citation by Gromley et al., which aims to identify genomic loci associated with migraines30. Although the paper has little to do with anxiety and depression, it uses NESDA data in its meta-analysis, because NESDA features DNA and migraine information for its study participants. As evidenced by its major topic MeSH terms, the said migraine citation covers three subject areas: SA1 ≡ Biological Sciences due to polymorphism content, SA3 ≡ Medical Sciences due to migraine content, and SA4 ≡ Technical Methods due to computational content. For a psychological study like NESDA, this citation represents an impressive cross-disciplinary outreach.
Second, we visit the citation by Jacobson et al., which aims to predict the onset of anxiety disorders through deep learning of participants’ digital biomarkers31. In this case, the digital biomarkers were actigraphy data acquired through wearable devices to feed a deep autoencoder and ensemble model. Papers like Jacobson’s represent a growing new trend. Recognizing the importance of anxiety and associated longitudinal studies, the motivation of these nascent efforts is to substitute labor-intensive data collection like NESDA, with studies based on data collected through ubiquitous sensors, which are more amenable to automation. As evidenced by its major topic MeSH terms, Jacobson’s citation connects psychological content (SA2) with a strong technical component (SA4), owing to its deep learning approach.
Third, we visit the citation by Dijkstra-Kersten et al., which aims to investigate the association between depressive/anxiety disorders and perceived financial strain32. The paper uses data from the NESDA cohort to document that not only income, but also perceived financial strain irrespective of income is a predictor of depressive and anxiety disorders. As evidenced by its major topic MeSH terms, the citation connects humanities (SA5), owing to its socioeconomic considerations, with psychological sciences (SA2), owing to its use of NESDA data.
Altogether, the thematic diversity of the citations we discussed draws from a set that includes all five subject areas. Hence, the citations of the NESDA paper have thematic diversity that either exceeds or is totally different than its own thematic diversity, which is constrained to just SA2 ≡ Psychological Sciences.
Cognitive literature group
From the Cognitive group, a representative publication is the “Requirement for Hippocampal CA3 NMDA Receptors in Associative Memory Recall”, authored by Nakazawa et al. and published in Science in 200233. As of April 29, 2023, this paper had 745 citations per iCite and a normalized citation score CN = 2.47 per Eq. (3). The paper provides indirect evidence for the involvement of the CA3 area of hippocampus in associative memory recall based on partial cues. The experiments that led to this conclusion were carried out with mutant mice with ablated CA3 cells. The mice exhibited radically different maze activities when presented with full cues versus partial cues. Accordingly, the publication’s content features a measure of convergence, drawing upon three subject areas: Biological Sciences (SA1) owing to its hippocampal content; Psychological Sciences (SA2) owing to its memory content; and, Technical Methods (SA4) owing to the genetic engineering of the mice involved in the experiments. Indeed, the SA vector for this publication is (overrightarrow {{mathscr{T}}}(p)={1,1,0,1,0}) and thus, its thematic diversity stands at Dp = 0.50 per Eq. (1). The mean thematic diversity of the paper’s citations stands at ({bar{D}}_{c}=0.52) per Eq. (2). Accordingly, Dp and ({bar{D}}_{c}) are on par, in contrast to the representative publications we analyzed from the Mixed and Affective groups, where the thematic diversity of the citations far exceeded the thematic diversity of the cited paper.
This is a typical pattern with many Cognitive publications, that is, they feature moderate convergence and they attract citations that are their mirror image. We believe this is due to the fact that Cognitive publications usually focus on brain science issues. These issues are quite complex and require a measure of convergent knowledge to be addressed. Unlike affective issues, however, brain issues are very specialized, and thus of interest mainly to the brain science community. For instance, consider memory function versus anxiety and depression. Memory function is an important question, but unlike anxiety and depression, is not directly related to a major societal problem. To substantiate these points, we will comment on three thematically similar articles that cite Nakazawa’s paper
First, we visit the citation by Neves et al. titled “Synaptic plasticity, memory, and the hippocampus: a neural network approach to causality”34. The paper was published in 2008 in Nature Reviews Neuroscience and addresses the role of hippocampus in memory, that is, a superset of the issues addressed in Nakazawa’s paper. As evidenced by its major topic MeSH terms, the said citation covers two subject areas: SA1 ≡ Biological Sciences, owing to its treatment of hippocampal anatomy and physiology; SA2 ≡ Psychological Sciences, owing to its treatment of memory.
Second, we visit the citation by Laura Lee Coglin titled “Rhythms of the hippocampal network”35. The paper was published in 2016 in Nature Reviews Neuroscience and addresses hippocampal rhythms in the form of theta, sharp wave-ripples, and gamma. These rhythms are believed to carry distinct functions in hippocampal memory processing. Coglin brings up Nakazawa’s paper because it points to the central role of the CA3 network in storage and retrieval of memories, and in this respect offers clues about the types of rhythms involved in such processes. As evidenced by its major topic MeSH terms, the said citation covers two subject areas: SA1 ≡ Biological Sciences, owing to its treatment of hippocampal anatomy and physiology; SA4 ≡ Technical Methods, owing to its treatment of electroencephalography.
Third, we visit the citation by Neunuebel and Knierim titled “CA3 retrieves coherent representations from degraded input: direct evidence for CA3 pattern completion and dentate gyrus pattern separation”36. The paper was published in 2014 in Neuron and provides direct neurophysiological evidence for pattern completion of severely degraded inputs in the DG-CA3 circuit. In this respect, Neunuebel and Knierim’s paper complements Nakazawa’s paper, which provided only indirect behavioral evidence for the functionality of CA3. As evidenced by its major topic MeSH terms, the said citation covers two subject areas: SA1 ≡ Biological Sciences, owing to its treatment of hippocampal anatomy and physiology; SA2 ≡ Psychological Sciences, owing to its treatment of memory.
Altogether, the thematic diversity of the representative citations we discussed draws from the thematic diversity of Nakazawa’s paper without ever exceeding it, that is, from the subject area set that includes SA1, SA2, and SA4.
Discussion
Research teams designed to harness the integrative advantages of convergence have emerged as a prominent mode of scientific production10. Such developments have been partly spurred by convergence’s successes in addressing certain grand challenges, such as the Human Genome Project (HGP)13. Nevertheless, the positive role of convergence has not always proved to be clear-cut. For instance, convergence in brain science has had mixed results4,5,6, motivating deeper studies of convergence in additional disciplines, particularly ones that appear to be on the march. In this context, affectivism is an ideal target of convergence investigation, because it is rooted in the affective sciences and attempts to bridge over to cognitive approaches9.
Accordingly, we set out to examine convergence in Cognitive vis-à-vis Affective vis-à-vis Mixed literature in psychological sciences and allied fields. In this analytic study design, the Cognitive literature group serves as control. The Affective and Mixed literature groups, which constitute affectivism trends, serve as neighboring groups but with purported broader reach9. This tri-field ecosystem is a natural experiment in convergence that brings insights not afforded by single field studies. Adding to that, a key methodological innovation of our work is accounting for convergence not only in the thematic content of publications but also in the thematic content of their citations. This approach relates to the following profound question: Does convergence feed upon convergence?
To address this question, we collected over half a million Affective, Cognitive, and Mixed publications, which provide a comprehensive reconstruction of convergent research in neighboring fields, but evolving from different perspectives and methodologies. The publication-level regression models indicate that: (a) The Mixed group is more impactful than the Affective group, and both are more impactful than the Cognitive group. (b) The Mixed group has the least convergent content. (c) The Cognitive group has the least convergent following.
In other words, the literature groups that represent affectivism not only have stronger citation impact but also broader reach across scientific fields. Notably, the Mixed group attains this broad reach despite its significantly more limited convergent content. Looking behind the numbers and in the actual publications indexed in our dataset, we traced this effect into broadly useful concepts that can be leveraged across scientific communities, from medicine to socioeconomic inquiry. Finally, these modeling results stand after controlling for number of authors and subject content in publications – two factors known to affect citation impact per other science of science research12,13.
Limitations
Our study reveals that convergence is not necessarily an omnipresent phenomenon in the fields that is encountered. The assumption thus far in the literature has been that in order to breed convergence you need to start with convergence37. This belief does not appear to hold. On the contrary, broadly useful tools of even mono-disciplinary origin can percolate into multiple fields creating a far richer convergent ecosystem than convergent tools of moderate utility. Although due to the regressional nature of our modeling it is not possible to claim causality, we can at least hypothesize that the rise of affectivism may be partly due to its multidisciplinary impact rather than its multidisciplinary pedigree.
Data availability
The data collected for this study are available in the Open Science Framework: https://osf.io/v8qxs/with https://doi.org/10.17605/OSF.IO/V8QXS.
Code availability
The R code used for analysis is available in GitHub: https://github.com/vvzhukov/Convergence-in-Affective-and-Cognitive-Sciences with https://doi.org/10.5281/zenodo.11284448.
References
-
Watson, J. B. Psychology as the behaviorist views it. Psychol. Rev. 20, 158–177 (1913).
Google Scholar
-
Miller, G. A., Eugene, G. & Pribram, K. H. Plans and the structure of behaviour. In Systems Research for Behavioral Science, 369–382 (Routledge, 2017).
-
Shiffrin, R. M. & Nosofsky, R. M. Seven plus or minus two: A commentary on capacity limitations. Psychol. Rev. 101, 357–361 (1994).
Google Scholar
-
Petersen, A. M., Ahmed, M. E. & Pavlidis, I. Grand challenges and emergent modes of convergence science. Hum. Soc. Sci. Commun. 8, 1–15 (2021).
-
Petersen, A. M., Arroyave, F. & Pavlidis, I. Methods for measuring social and conceptual dimensions of convergence science. Research Evaluation https://doi.org/10.1093/reseval/rvad020 (2023).
-
Naddaf, M. Europe spent €600 million to recreate the human brain in a computer. How did it go? Nature 620, 718–720 (2023).
Google Scholar
-
Núñez, R. et al. What happened to cognitive science? Nat. Hum. Behav. 3, 782–791 (2019).
Google Scholar
-
Davidson, R., Scherer, K. & Goldsmith, H. The role of affect in decision making. In Handbook of Affective Sciences, vol. 3, 619–642 (Oxford University Press, 2003).
-
Dukes, D. et al. The rise of affectivism. Nat. Hum. Behav. 5, 816–820 (2021).
Google Scholar
-
Pavlidis, I., Akleman, E. & Petersen, A. M. From Polymaths to Cyborgs—Convergence Is Relentless. Am. Scientist 110, 196–200 (2022).
Google Scholar
-
Waltman, L. A review of the literature on citation impact indicators. J. Informetr. 10, 365–391 (2016).
Google Scholar
-
Tahamtan, I. & Bornmann, L. Core elements in the process of citing publications: Conceptual overview of the literature. J. Informetr. 12, 203–216 (2018).
Google Scholar
-
Petersen, A. M., Majeti, D., Kwon, K., Ahmed, M. E. & Pavlidis, I. Cross-disciplinary evolution of the genomics revolution. Sci. Adv. 4, eaat4211 (2018).
Google Scholar
-
Basson, I., Blanckenberg, J. P. & Prozesky, H. Do open access journal articles experience a citation advantage? Results and methodological reflections of an application of multiple measures to an analysis by WoS subject areas. Scientometrics 126, 459–484 (2021).
Google Scholar
-
Bagchi, C., Malmi, E. & Grabowicz, P. Effects of research paper promotion via arXiv and X. arXiv preprint arXiv:2401.11116 https://doi.org/10.48550/arXiv.2401.11116 (2024).
-
National Library of Medicine (US). Medical Subject Headings, vol. 41 (US Department of Health and Human Services, Public Health Service, 2000).
-
Petersen, A. M. Evolution of biomedical innovation quantified via billions of distinct article-level MeSH keyword combinations. Adv. Complex Syst. 25, 2150016 (2022).
Google Scholar
-
Stirling, A. A general framework for analysing diversity in science, technology and society. J. R. Soc. Interface 4, 707–719 (2007).
Google Scholar
-
Leydesdorff, L., Wagner, C. S. & Bornmann, L. Betweenness and diversity in journal citation networks as measures of interdisciplinarity – A tribute to Eugene Garfield. Scientometrics 114, 567–592 (2018).
Google Scholar
-
Leydesdorff, L., Wagner, C. S. & Bornmann, L. Interdisciplinarity as diversity in citation patterns among journals: Rao-Stirling diversity, relative variety, and the Gini coefficient. J. Informetr. 13, 255–269 (2019).
Google Scholar
-
Hutchins, B. I. et al. The NIH Open Citation Collection: A public access, broad coverage resource. PLOS Biol. 17, e3000385 (2019).
Google Scholar
-
Kozlowski, D., Andersen, J. P. & Larivière, V. The decrease in uncited articles and its effect on the concentration of citations. J. Assoc. Inf. Sci. Technol. 75, 188–197 (2024).
Google Scholar
-
Radicchi, F., Fortunato, S. & Castellano, C. Universality of citation distributions: Toward an objective measure of scientific impact. Proc. Natl Acad. Sci. USA 105, 17268–17272 (2008).
Google Scholar
-
Petersen, A. M., Pavlidis, I. & Semendeferi, I. A quantitative perspective on ethics in large team science. Sci. Eng. Ethics 20, 923–945 (2014).
Google Scholar
-
Lupien, S. J., McEwen, B. S., Gunnar, M. R. & Heim, C. Effects of stress throughout the lifespan on the brain, behaviour and cognition. Nat. Rev. Neurosci. 10, 434–445 (2009).
Google Scholar
-
Herman, J. P. et al. Regulation of the hypothalamic-pituitary-adrenocortical stress response. Compr. Physiol. 6, 603 (2016).
Google Scholar
-
Epel, E. S. et al. More than a feeling: A unified view of stress measurement for population science. Front. Neuroendocrinol. 49, 146–169 (2018).
Google Scholar
-
Chanda, M. L. & Levitin, D. J. The neurochemistry of music. Trends Cogn. Sci. 17, 179–193 (2013).
Google Scholar
-
Penninx, B. W. et al. The Netherlands Study of Depression and Anxiety (NESDA): rationale, objectives and methods. Int. J. Methods Psychiatr. Res. 17, 121–140 (2008).
Google Scholar
-
Gormley, P. et al. Meta-analysis of 375,000 individuals identifies 38 susceptibility loci for migraine. Nat. Genet. 48, 856–866 (2016).
Google Scholar
-
Jacobson, N. C., Lekkas, D., Huang, R. & Thomas, N. Deep learning paired with wearable passive sensing data predicts deterioration in anxiety disorder symptoms across 17–18 years. J. Affect. Disord. 282, 104–111 (2021).
Google Scholar
-
Dijkstra-Kersten, S. M., Biesheuvel-Leliefeld, K. E., van der Wouden, J. C., Penninx, B. W. & van Marwijk, H. W. Associations of financial strain and income with depressive and anxiety disorders. J. Epidemiol. Community Health 69, 660–665 (2015).
Google Scholar
-
Nakazawa, K. et al. Requirement for hippocampal CA3 NMDA receptors in associative memory recall. Science 297, 211–218 (2002).
Google Scholar
-
Neves, G., Cooke, S. F. & Bliss, T. V. Synaptic plasticity, memory and the hippocampus: a neural network approach to causality. Nat. Rev. Neurosci. 9, 65–75 (2008).
Google Scholar
-
Colgin, L. L. Rhythms of the hippocampal network. Nat. Rev. Neurosci. 17, 239–249 (2016).
Google Scholar
-
Neunuebel, J. P. & Knierim, J. J. CA3 retrieves coherent representations from degraded input: direct evidence for CA3 pattern completion and dentate gyrus pattern separation. Neuron 81, 416–427 (2014).
Google Scholar
-
Arnold, A. & Bowman, K. (eds.). Fostering the culture of convergence in research: Proceedings of a Workshop (National Academies Press, 2019).
Acknowledgements
Part of this research was funded through the Eckhard-Pfeiffer Distinguished Professorship Fund at the University of Houston. The fund’s administration had no role in study design, data collection and analysis, decision to publish or preparation of the manuscript.
Author information
Authors and Affiliations
Contributions
Vitalii Zhukov collected data and developed methods, Alexander M. Petersen advised on methods and edited manuscript, Daniel Dukes and David Sander provided the MeSH set of keywords and edited manuscript, Panagiotis Tsiamyrtzis advised on methods and edited manuscript, Ioannis Pavlidis designed research and wrote manuscript. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
: Communications Psychology thanks Maxime Sainte-Marie and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Primary Handling Editor: Jennifer Bellingtier. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Peer Review File
Supplementary Materials
Reporting Summary
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
Reprints and permissions
About this article
Cite this article
Zhukov, V., Petersen, A.M., Dukes, D. et al. Science convergence in affective research is associated with impactful multidisciplinary appeal rather than multidisciplinary content.
Commun Psychol 2, 83 (2024). https://doi.org/10.1038/s44271-024-00129-x
-
Received: 23 November 2023
-
Accepted: 12 August 2024
-
Published: 04 September 2024
-
DOI: https://doi.org/10.1038/s44271-024-00129-x