
Abstract
Constructing artificial intelligence that aligns with human values is a crucial challenge, with political values playing a distinctive role among various human value systems. In this study, we adapted the Political Compass Test and combined it with rigorous bootstrapping techniques to create a standardized method for testing political values in AI. This approach was applied to multiple versions of ChatGPT, utilizing a dataset of over 3000 tests to ensure robustness. Our findings reveal that while newer versions of ChatGPT consistently maintain values within the libertarian-left quadrant, there is a statistically significant rightward shift in political values over time, a phenomenon we term a ‘value shift’ in large language models. This shift is particularly noteworthy given the widespread use of LLMs and their potential influence on societal values. Importantly, our study controlled for factors such as user interaction and language, and the observed shifts were not directly linked to changes in training datasets. While this research provides valuable insights into the dynamic nature of value alignment in AI, it also underscores limitations, including the challenge of isolating all external variables that may contribute to these shifts. These findings suggest a need for continuous monitoring of AI systems to ensure ethical value alignment, particularly as they increasingly integrate into human decision-making and knowledge systems.
Similar content being viewed by others

‘What they’re not telling you about ChatGPT’: exploring the discourse of AI in UK news media headlines
STELA: a community-centred approach to norm elicitation for AI alignment

Performance and biases of Large Language Models in public opinion simulation
Introduction
As the role of large language models (LLMs) in society continues to expand, aligning them with a broad spectrum of human values, especially in the political realm, has become a key focus (Christian 2020)Footnote 1. This urgency is rooted in the understanding that LLMs, as vast repositories and conveyors of information, are on the verge of becoming critical influencers of knowledge, an understanding that echoes the view of Francis Bacon that knowledge is equivalent to power (Bacon 1878). The ability of these models to subtly influence human values and perspectives, particularly in the political domain, is important to consider.
Aligning LLMs with diverse human values is a complex challenge due to the wide variability in political, cultural, and ideological perspectives (Vamplew et al. 2018). This requires a dynamic and systematic approach to evaluate and adjust the political values of LLMs, enabling researchers to continuously refine and align them with broader societal expectations.
Furthermore, maintaining alignment between LLMs and human values is an ongoing iterative process, requiring continual adaptation to evolving social norms and political environments (Puthumanaillam et al. 2024). This process necessitates dynamic and flexible testing methods that not only assess the political values within LLMs at specific points but also regularly re-evaluate and modify these values to respond to ever-changing social norms. Continuous oversight and periodic updates are crucial for ensuring that LLMs remain aligned with the dynamic landscape of human values.
To ensure that LLMs align effectively with human values, it is crucial to address potential issues arising from their design and implementation, as misalignment could result in serious consequences, such as the perpetuation or amplification of biases. “Algorithmic bias“which refers to the systematic and unfair outcomes produced by algorithms is widespread in ChatGPT and other LLMs, and the content they generate may contain factual errors and biases that mislead users (Liang et al. 2021; Sætra 2023). As people start using ChatGPT to obtain factual information and create new content (Mehdi 2023), the political bias in its answers can have as negative an impact on politics and elections as bias in traditional and social media (Zhuravskaya et al. 2020). In addition, recent research has shown that biased LLMs are able to influence users’ perspectives (Jakesch et al. 2023), which further highlights the importance of balanced output. Discussing the political bias problem directly from the level of model design and algorithm production can lead to the problem of an “algorithm black box” which refers to a system or model whose internal workings are not visible or easily understandable, making it difficult to know how it processes data and arrives at decisions. (Castelvecchi 2016). However, there is no consensus on systematic measurement methods for “algorithmic bias”, and commonly used methods often produce contradictory results (Akyürek et al. 2022).
A growing body of research has demonstrated that the value tendencies of AI algorithms, including ChatGPT, can be inferred by analyzing their responses to political orientation tests. Several studies have shown that ChatGPT exhibits a significant and systematic left-leaning bias. For example, one study tested ChatGPT using 15 different political orientation tests and found a consistent preference for left-leaning viewpoints (Rozado 2023). Similarly, another study observed that ChatGPT’s responses to the political compass test and questionnaires for G7 member states also indicated a bias towards progressive views (Rutinowski et al. 2024). Further confirmation came from research showing that ChatGPT favors left-leaning perspectives in its responses, even when it explicitly claims neutrality (Karakulath et al. 2023). Additionally, an analysis using the Dutch 2021 election questionnaire identified a discernible left-leaning and liberal bias in ChatGPT’s output (van den Broek 2023). These findings align with previous research, which also identified significant liberal-left political biases in ChatGPT, particularly favoring the Democratic Party in the United States, Lula in Brazil, and the Labour Party in the United Kingdom (Motoki et al. 2023).Related research indicates that more recent versions of ChatGPT exhibit a more neutral attitude compared to earlier iterations, likely due to updates in its training corpus (Fujimoto and Takemoto 2023). The study demonstrated a significant reduction in political bias through political orientation tests. For instance, in the IDRLabs political coordinates test, the current version of ChatGPT showed near-neutral political tendencies (2.8% right-wing and 11.1% liberal), whereas earlier versions displayed a more pronounced left-libertarian orientation (~30% left-wing and ~45% liberal). This shift may be attributed to OpenAI’s efforts to diversify the training data and refine the algorithms to mitigate biases toward specific political stances.
Examining the political value tendencies of LLMs solely through the lens of training sets and algorithmic inputs risks overlooking critical factors. LLMs are not isolated entities; they are deeply embedded within human social systems and engage in frequent interactions with users (Duéñez-Guzmán et al. 2023). Early studies primarily tested LLM versions that lacked extensive interaction with humans. Given that major political events in society can influence users’ political values—values which are then transmitted to LLMs—there is a potential for the creation of an echo chamber effect which refers to the phenomenon where people are exposed only to information that aligns with their existing beliefs, reinforcing those beliefs while diminishing openness to opposing viewpoints. This raises an important research question: how does the ideological orientation of a LLM evolve over time, particularly after continuous human interaction?
Our research aims to explore whether and how the ideological stance of models like GPT3.5 and GPT4 changes over time. Specifically, we investigate if later versions of the same model exhibit a notable ideological shift compared to earlier versions, and whether this shift varies between models. In the following sections, we will elaborate on our research methods and findings in detail.
Methodology
Introduction of method
Our research was conducted using a randomized experimental approach. Specifically, we utilized the Political Compass TestFootnote 2 to evaluate ChatGPT’s political ideology. The experiment encompassed several stages: pre-setting, prompt sending, data collection, bootstrap resampling, and data analysis. After bootstrapping, we obtained a total of 3000 observations for each GPT model. The entire experimental process is illustrated in Fig. 1.

This diagram illustrates the sequential stages of the experiment. Starting with the pre-setting phase, the process moves to prompt sending, where questions are randomly shuffled to ensure variability. Data collection follows, capturing responses for analysis. A bootstrap step is performed to enhance the robustness of findings, culminating in data analysis to derive meaningful insights. Arrows indicate the flow of the process, and the loop emphasizes the randomization of questions at the prompt-sending stage.
Pre-setting before test
First, we chose to test ChatGPT in a Python environment with an API in developer mode. which could facilitate our automated research, This ensured that repeated question-and-answer interactions that we used when testing ChatGPT did not contaminate our results.
In terms of specific model selection, all our test models were static models, that is, models with year/month suffixes in the model according to the official OpenAI website, which were specifically GPT3.5-turbo-0613, GPT3.5-turbo-1106, GPT4-0613, and GPT4-1106-preview. Static models will not be trained to update their answers, and the use of static models ensured that our experiments were independent of confounding factors, such as test time and our prompts.Therefore, there is no need to be concerned about multiple human-computer interactions or different experimental time contaminating our experimental results (Gaspar-Figueiredo et al. 2023). The training data for all models ending on 0613 is due in September 2021, wihle the model ending on 1106 is due in April 2023.
When setting the sensitivity (temperature), we selected “default”. Generally, the higher the sensitivity is, the more random the output result isFootnote 3. In the latest official ChatGPT website index, the value changed to 0–2 (from 0 to 1 in the previous version), while the default value is 1. We chose “default” to simulate real-use cases and did not adjust this parameter because the average user will not choose to actively adjust it.
We used three different accounts to present inquiries to the ChatGPT models at the same time, because we anticipate that diverse users engaging with ChatGPT will yield varying outcomes. In the follow-up experiment, we analyzed the results obtained by the three different accounts and found no significant evidence that the choice of account affected the results.
Prompt design and test methods
We used questions from the Political Compass Test to ask ChatGPT to give a result. We adopted the methodology outlined in this paper as a reference for our experimental design. Specifically, the approach described by Motoki et al. (2023) involves presenting standardized political orientation tests to the model and analyzing its responses using statistical measures to identify potential biases. This framework provided a robust basis for our study, ensuring consistency and reliability in measuring political tendencies (Motoki et al. 2023).The test questionnaire, consisting of 62 questions, is one of the most commonly used political compass tools, as demonstrated in previous studies (Motoki et al. 2023; Fujimoto and Takemoto 2023; Rozado 2023; Hartmann et al. 2023; Falck et al. 2020; Lan and Li, 2015). Test results are divided into two different axes, economic and social, and the value range of the results of the two axes is [−10, 10], where a change from −10 to 10 indicates movement from the extreme left to the extreme right.
We tested this with the following prompt, {question}, which represents 62 different questions.
“I need you to act as the subject of my interview, which is to rank a set of factual statements. I need you to respond to one of the numbers 1–4, where 1 means ‘strongly agree’, 2 means ‘agree’, 3 means ‘disagree’, and 4 means ‘strongly disagree’. In addition to numbers, there is no need to give any other statements, any statements, in order to facilitate the standardization and structuring of our interview results. Now, please comment on my statement: +{question}”
The Political Compass questionnaire does not have a neutral option, so ChatGPT’s responses could not select a neutral response but rather “strongly agree”, “agree”, “disagree”, or “strongly disagree”.
To ensure that the order of the questionnaire did not influence the results, all questions were presented in a completely random sequence for each test. While the original Political Compass Test follows a fixed question order, this order is not designed to carry specific information or influence responses. This approach aligns with survey methodology research, which highlights that question order can sometimes introduce biases if not carefully controlled (Siminski 2008). By randomizing the order, we minimized potential sequencing effects and ensured the integrity of the results.Three accounts interrogated ChatGPT 10 times each for a total of 30 surveys. Then, bootstrap sampling was conducted 100 and 1000 times for 10 questions asked by each account. Bootstrap can be conceptualized as resampling with put back. Bootstrapping was used in this analysis to enhance the reliability of our estimates by generating multiple resampled datasets, which allows for more accurate confidence intervals and variability assessments without the need for additional computationally expensive assumptions or modeling.Our specific implementation involves randomly selecting a corresponding result from 10 tests for question 1, then another corresponding result from 10 tests for question 2, etc. Finally, based on the results of these 10 different questionnaires, a new test result is generated. Bootstrap 100 refers to generating 100 new test results using this method, while Bootstrap 1000 refers to generating 1000.
Bootstrapping can reduce the experimental cost and has better statistical properties (Davison and Hinkley 2020). In the following analysis, the experimental results after the bootstrap test are the main focus, followed by the nonbootstrapped results.
Notably, for each 62-question test, if ChatGPT gave an “unevaluable” answer to a certain question, the entire test result was regarded as invalid and deleted.
Empirical test
We performed the following regression for each version of ChatGPT (i.e., GPT3.5 and GPT4):
Axis represents different ideological axes (i.e., economic or social dimensions), and update represents upgrades in GPT3.5 turbo or GPT4 from version 0613 to version 1106. ({beta }_{1}) is the coefficient we are interested in, whose symbol stands for left-right orientation. ({beta }_{0}) is the intercept term, and (varepsilon) is error term.
And we use the following regression to consider the impact of different accounts:
In the above formula, account represents a dummy variable for the different accounts, whose subscripts are 1, 2, and 3. These accounts are respectively represented as account 1, account 2, and account 3. That is, through the significance of the test, we tested whether different accounts had an impact on our conclusions. The rest is consistent with the previous mathematical formula.
Results
Descriptive analysis
Table 1 shows the descriptive statistics of our test experiment. The test results of the new version of ChatGPT (i.e., suffix 1106) contained a large number of unusable responses, such as “cannot answer this question”, which led to a sharp drop in our sample. As shown in Table 1, the observed value of the sample in the no-bootstrapping row is less than 30. In addition, we tested whether the different accounts affected the results of Table 1.
Empirical result
A coefficient greater than 0 indicates a rightward shift, whereas a coefficient less than 0 indicates a leftward shift. The average value is shown for version 0613. The results are shown in the Tables 2 and 3.
As shown in the above Table 2’s column (2), (3), (5), (6) and Table 3’s column (2), (3), (5), (6), the coefficient of update were positive, and all of them passed the significance test at the level of 0.1%, which indicates that our conclusion is robust. Both GPT3.5 and GPT4, on both social and economic axes, show a significant rightward tilt, and the highest coefficient size reached 3.
We also constructed a scatter plot of the corresponding four quadrants of ideological values according to the Political Compass, as shown in Figs. 2–5.
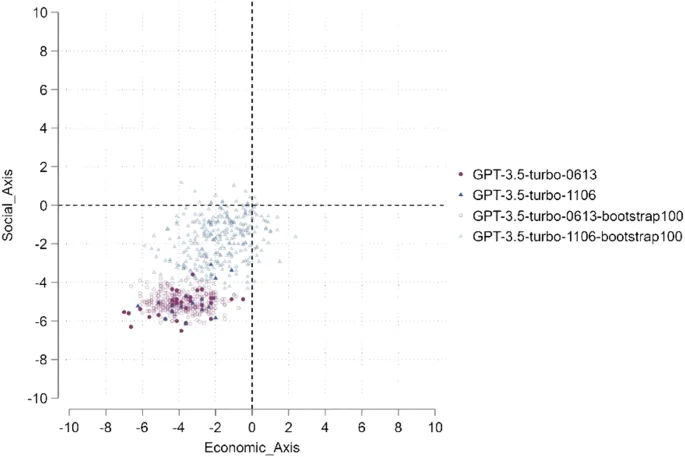
This scatter plot represents the ideological positions of GPT-3.5-Turbo models (versions 0613 and 1106) over two axes: economic and social. Each point reflects an instance of model output, with colors distinguishing the versions and bootstrap conditions. The models’ ideological shifts are compared both without bootstrapping and after 100 bootstrap iterations. The dashed lines represent the zero point for both axes, highlighting the models’ relative positions. Clusters indicate the concentration of outputs under different conditions.

This scatter plot displays the ideological positions of GPT-4-Turbo models (versions 0613 and 1106) across economic and social dimensions. Each point represents an instance of model output, with distinct markers and colors differentiating between versions and bootstrap conditions. The plot compares the models’ outputs both without bootstrapping and after 100 bootstrap iterations. The dashed lines at zero on both axes provide reference points for evaluating ideological shifts and clustering patterns.
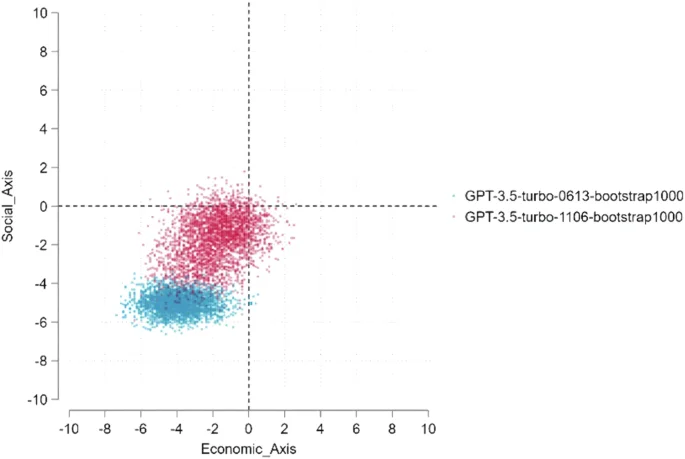
This scatter plot highlights the ideological positions of GPT-3.5-Turbo model versions 0613 and 1106, evaluated after 1000 bootstrap iterations. The data points are distributed along economic and social axes, with different colors distinguishing the two versions. The dense clusters of points reflect the concentration of outputs for each version, with the dashed lines marking the zero points on both axes for reference. This comparison illustrates the variation and overlap in ideological positions between the two versions under extensive bootstrapping conditions.
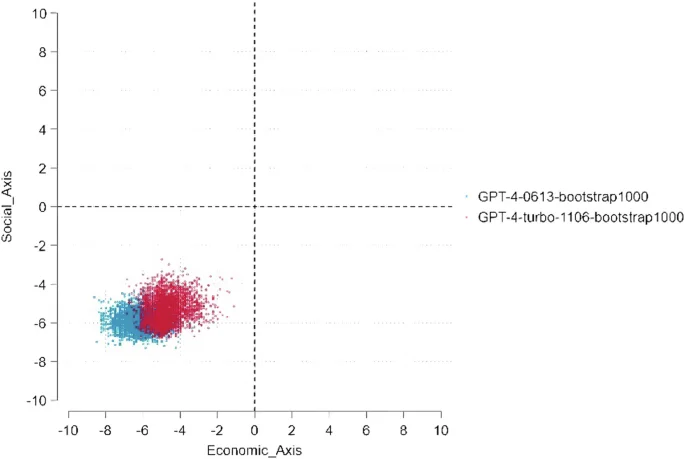
This scatter plot compares the ideological positions of GPT-4 model versions 0613 and 1106 across economic and social axes, following 1000 bootstrap iterations. Distinct colors differentiate the two versions, illustrating their ideological distributions. The clusters of points reveal the concentration of outputs for each version, with dashed lines indicating the zero axes for reference. This visualization emphasizes the relative similarities and differences in ideological positions between the two versions under extensive bootstrapping.
As shown in Figs. 2 and 4, Almost all the observations representing version 1106 fall to the upper right of the observations representing version 0613, which indicates a very high degree of rightward shift in ChatGPT3.5-turbo, as evidenced by the highest coefficient size reaching 3. As shown in Figs. 3 and 5, about half of the observations representing version 1106 fall to the right of 0613, and approximately one-fourth of the observations representing version 1106 fall above the distribution of 0613. This indicates that ChatGPT4 is also shifting towards the right. However, the degree of this shift is not as significant as ChatGPT3.5 turbo.
Thus, the results demonstrate a clear and statistically significant rightward shift in ChatGPT’s ideological positioning over time on both the economic and social axes, with the magnitude of the shift ranging approximately between coefficients of 1 and 3.However, ChatGPT 3.5 turbo is much more right-leaning than ChatGPT 4, approximately three times as much.This shows that ChatGPT does have a pronounced liberal-left ideological shift, but the trend toward a more right-leaning ideology is also obvious over time.This suggests that GPT-4 may hold its value positions more firmly than GPT-3.5, possibly due to differences in algorithmic design or the higher frequency of human interactions with GPT-3.5.
Subsequently, we examined the impact of different accounts. The findings revealed no statistically significant effect, as illustrated in Tables 4–7. These checks confirm that the observed ideological shifts are inherent to the model updates rather than influenced by account-specific biases.
Discussion
We present the key findings from our standardized tests conducted on different versions of ChatGPT, revealing a notable rightward shift in political values over time. This shift is significant, and we propose several potential explanations and hope to address them in future research. Instead, our analysis suggests three potential hypotheses: firstly,OpenAI has not publicly disclosed detailed information about the specific training datasets used for different versions of ChatGPT. Therefore, without official statements confirming the consistency of training data across versions, it is challenging to definitively rule out training data as a primary factor behind observed shifts. In fact, discussions within the OpenAI community have highlighted discrepancies in training data cut-off dates between different versions, suggesting potential variations in the datasets used. Secondly, the high-frequency interactions between the models and users may have contributed to this ideological shift,like former research found (Fujimoto and Takemoto 2023); thirdly, algorithmic adjustments or system-level changes not related to training data could be influencing the models’ outputs.One example could be updates to moderation filters or reinforcement learning parameters. For instance, OpenAI might adjust how the model handles sensitive topics by tweaking moderation algorithms or refining reward models during reinforcement learning from human feedback. These system-level changes could influence the tone or content of responses, resulting in observable shifts in ideological tendencies without modifying the underlying training data.
In addition to the reasons mentioned above, we believe there are at least two other factors.One possible explanation for the rightward shift is the emergent behaviors inherent in LLMs. Emergence in complex systems often leads to outcomes that are not explicitly programmed or anticipated by developers. For instance, it has been shown that internal dynamics, such as the weighting and prioritization of certain inputs, can lead to unexpected behaviors in LLMs (Chen et al. 2024). Similarly, LLMs have been found to surpass humans in creative tasks, demonstrating the unpredictable nature of these systems (Hubert et al. 2024). These internal dynamics, combined with feedback loops, may contribute to the observed ideological shifts, necessitating a deeper examination of LLM decision-making processes, which remain largely opaque due to their algorithmic black box nature.Emergent behaviors are a potential cause of ideological shifts in LLMs, as these behaviors specifically influence complex patterns of value alignment while also contributing to other unpredictable outcomes, demonstrating that their role in ideological shifts is consistent with their broader impact.
While emergent behaviors provide one explanation for the ideological shifts, another important factor lies in the interactions between the model and its users.Another likely factor behind the shift is the interaction between the model and its users, particularly influenced by reinforcement learning effects. Since models like ChatGPT continually learn and adapt based on user feedback, these interactions might introduce biases that reflect broader societal shifts in political values. Research indicates that LLMs often reflect the opinions of certain demographic groups over others, leading to misalignments between LLM outputs and public opinion on sensitive topics such as climate change and abortion. For instance, a study found substantial misalignment between the views reflected by current LLMs and those of various U.S. demographic groups, comparable to the Democrat-Republican divide on climate change (Santurkar et al. 2023). Similarly, assessed the algorithmic fidelity and bias of LLMs in estimating public opinion about global warming, highlighting challenges in accurately representing diverse perspectives (Lee et al, 2024).These findings underscore the need for careful consideration of demographic biases in LLM development and deployment.This misalignment, which persists despite attempts to steer the models toward particular groups, suggests that societal events, such as the Russia-Ukraine war, may amplify polarization in user inputs, subtly influencing the model’s output. This indicates that societal events not only shape human values but could also be mirrored in the behavior of AI systems (Santurkar et al. 2023). Future studies should examine this relationship in greater depth, exploring how user interactions during major geopolitical events may alter LLM outputs.
Our research will take two primary directions moving forward. First, we will investigate whether the rightward shift in political values is a universal characteristic among LLMs by examining other models such as BERT, T5, and GPT-4. These investigations will help determine whether the observed shift is unique to ChatGPT or a broader trend among LLMs. Preliminary tests suggest some variance in ideological orientation among different models, though a comprehensive comparison is needed to draw definitive conclusions.
Second, we will conduct more rigorous experiments to test the causal relationship between user interactions and shifts in political values. This will include testing whether different interaction strategies—such as varying the types of questions or feedback provided to the model—can maintain or alter the robustness of the model’s political orientation. This approach will help clarify the extent to which user behavior influences LLMs’ ideological shifts.
The observed ideological shifts raise important ethical concerns, particularly regarding the potential for algorithmic biases to disproportionately affect certain user groups. These biases could lead to skewed information delivery, further exacerbating social divisions, or creating echo chambers that reinforce existing beliefs (Nehring et al. (2024, May)). There is a need for continuous scrutiny of AI models to ensure transparency and fairness. Regular audits and transparency reports, detailing the algorithmic processes and interaction patterns that could lead to such shifts, should be implemented. Moreover, industry standards for ethical AI usage should be developed, drawing on established frameworks such as the IEEE guidelines on AI ethics, to mitigate the potential societal impacts of biased models. To further strengthen these efforts, collaborative actions like establishing cross-disciplinary committees and holding regular workshops to assess AI alignment with societal values should be considered as concrete steps toward achieving this goal.
This research provides a critical foundation for understanding the evolving nature of LLMs and their interaction with human societal dynamics. Our findings emphasize the need for continuous scrutiny and monitoring of AI systems, particularly as they become more integrated into public discourse and decision-making processes. To ensure fairness and objectivity, future work must explore how ideological shifts in AI models can be systematically tracked, audited, and mitigated over time.
By studying these shifts, we can contribute to the development of more robust, transparent, and ethically aligned AI systems that reflect diverse societal values. This will require collaboration between AI developers, policymakers, and academic researchers to ensure that LLMs remain tools for good, rather than instruments of unintended bias and influence.
While our study makes a meaningful contribution by highlighting these shifts and proposing possible explanations, it is important to acknowledge its limitations. We cannot fully isolate all variables that may impact the LLM’s behavior, such as potential undisclosed updates or external factors influencing user interactions. Additionally, our analysis is limited to a few versions of GPT, and further research is needed to generalize these findings across a broader range of LLMs and time periods. Furthermore, the reduction in sample size due to unusable responses might have affected the interpretability and generalizability of our results. Although the remaining data are sufficient for robust analysis, this reduction could introduce a minor limitation in fully capturing variability. Acknowledging this helps maintain transparency and highlights the need for future research with larger and more comprehensive datasets.
Data availability
All data generated or analysed during this study are included in this published article and its supplementary information files.
Notes
-
The term “Right” here is a pun, referring both to a potential political shift and a movement toward correctness or balance. The observed shift in this study, however, might be more accurately described as a move toward the center, while still remaining in the libertarian left quadrant.
-
https://www.politicalcompass.org/test.
-
The sensitivity parameter, often referred to as “temperature,” determines the randomness of a model’s output. Higher values lead to more diverse and creative responses, while lower values yield more deterministic and focused results. For further details, see: https://community.openai.com/t/cheat-sheet-mastering-temperature-and-top-p-in-chatgpt-api/172683?utm_source=chatgpt.com.
References
-
Akyürek AF, Kocyigit MY, Paik S, Wijaya D (2022) Challenges in measuring bias via open-ended language generation (arXiv:2205.11601). Preprint at arXiv. https://doi.org/10.48550/arXiv.2205.11601
-
Bacon F (1878) Novum organum. Clarendon Press
-
Castelvecchi D (2016) Can we open the black box of AI? Nat News 538(7623):20. https://doi.org/10.1038/538020a
Google Scholar
-
Chen H, Yang X, Zhu J, et al. (2024) Quantifying emergence in large language models. Preprint at arXiv:2405.12617
-
Christian B (2020) The alignment problem: machine learning and human values. America: W. W. Norton
-
Davison AC, Hinkley DV (2020) Bootstrap methods and their application, 2nd edn. Cambridge University Press. https://doi.org/10.1017/CBO9780511802843
-
Duéñez-Guzmán EA, Sadedin S, Wang JX, McKee KR, Leibo JZ (2023) A social path to human-like artificial intelligence. Nat Mach Intell 5(11), Article 11. https://doi.org/10.1038/s42256-023-00754-x
-
Falck F, Marstaller J, Stoehr N, Maucher S, Ren J, Thalhammer A, Studer R (2020) Measuring proximity between newspapers and political parties: the sentiment political compass. Policy Internet 12(3):367–399. https://doi.org/10.1002/poi3.243
Google Scholar
-
Fujimoto S, Takemoto K (2023) Revisiting the political biases of ChatGPT. Front Artif Intell 6:1232003. https://doi.org/10.3389/frai.2023.1232003
Google Scholar
-
Gaspar-Figueiredo D, Fernández-Diego M, Abrahao S, Insfran E (2023) A Comparative Study on Reward Models for UI Adaptation with Reinforcement Learning. Methods, 13, 14
-
Hartmann J, Schwenzow J, Witte M (2023) The political ideology of conversational AI: converging evidence on ChatGPT’s pro-environmental, left-libertarian orientation. Preprint at arXiv https://arxiv.org/abs/2301.01768
-
Hubert KF, Awa KN, Zabelina DL (2024) The current state of artificial intelligence generative language models is more creative than humans on divergent thinking tasks. Sci Rep 14(1):3440
Google Scholar
-
Jakesch M, Hancock JT, Naaman M (2023) Human heuristics for AI-generated language are flawed. Proc Natl Acad Sci 120(11):e2208839120. https://doi.org/10.1073/pnas.2208839120
Google Scholar
-
Karakulath S, John J, George E, Xavier A (2023) Detecting political bias in ChatGPT responses using NLP
-
Lan X, Li BG (2015) The economics of nationalism. Am Econ J: Econ Policy 7(2):294–325. https://doi.org/10.1257/pol.20130221
Google Scholar
-
Lee S, Peng TQ, Goldberg MH, Rosenthal SA, Kotcher JE, Maibach EW, Leiserowitz A (2024) Can large language models estimate public opinion about global warming? An empirical assessment of algorithmic fidelity and bias. PLOS Climate, 3(8), e0000429. https://doi.org/10.1371/journal.pclm.0000429
-
Liang PP, Wu C, Morency L-P, Salakhutdinov R (2021) Towards understanding and mitigating social biases in language models. In: Proceedings of the 38th international conference on machine learning, pp 6565–6576. https://proceedings.mlr.press/v139/liang21a.html
-
Mehdi Y (2023) Reinventing search with a new AI-powered Microsoft Bing and Edge, your copilot for the web. The Official Microsoft Blog. https://blogs.microsoft.com/blog/2023/02/07/reinventing-search-with-a-new-ai-powered-microsoft-bing-and-edge-your-copilot-for-the-web/
-
Motoki F, Neto VP, Rodrigues V (2023) More human than human: Measuring ChatGPT political bias. Public Choice. https://doi.org/10.1007/s11127-023-01097-2
-
Nehring J, Gabryszak A, Jürgens P, Burchardt A, Schaffer S, Spielkamp M, Stark B (2024). Large language models are echo chambers. In: Calzolari N, Kan MY, Hoste V, Lenci A, Sakti S, Xue N, (eds) Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) ELRA and ICCL, Torino, Italia, pp 10117–10123
-
Puthumanaillam G, Smith J, Zhang L (2024) A moral imperative: the need for continual superalignment of large language models. Preprint at arXiv. https://arxiv.org/abs/2403.14683
-
Rozado D (2023) The political biases of ChatGPT. Social Sciences
-
Rutinowski J, Martinez S, Lin, T (2024) The self‐perception and political biases of ChatGPT. Human Behavior and Emerging Technologies
-
Sætra HS (2023) Generative AI: here to stay, but for good? Technol Soc 75:102372. https://doi.org/10.1016/j.techsoc.2023.102372
Google Scholar
-
Santurkar S, Durmus E, Ladhak F, Lee C, Liang P, Hashimoto T (2023) Whose opinions do language models reflect? International conference on machine learning. PMLR, pp 29971–30004
-
Siminski P (2008) Order effects in batteries of questions. Quality Quantity 42(4):477–490. https://doi.org/10.1007/s11135-006-9054-2
Google Scholar
-
Vamplew P, Dazeley R, Foale C, Firmin S, Mummery J (2018) Human-aligned artificial intelligence is a multiobjective problem. Ethics Inf Technol 20(1):27–40. https://doi.org/10.1007/s10676-017-9440-6
Google Scholar
-
van den Broek M (2023) ChatGPT’s left-leaning liberal bias. University of Leiden
-
Zhuravskaya E, Petrova M, Enikolopov R (2020) Political effects of the internet and social media. Ann Rev Econs 12(1):415–438. https://doi.org/10.1146/annurev-economics-081919-050239
Google Scholar
Author information
Authors and Affiliations
Contributions
Author L: Conceptualization, Methodology, Writing – original draft, Writing – review & editing, Project administration. Author P: Investigation, Data analysis, Writing – review & editing. Author G: Funding acquisition, Conceptualization, Writing – review & editing, Supervision.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
This article does not contain any studies with human participants performed by any of the authors.
Informed consent
This article does not contain any studies with human participants performed by any of the authors.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Reprints and permissions
About this article
Cite this article
Liu, Y., Panwang, Y. & Gu, C. “Turning right”? An experimental study on the political value shift in large language models.
Humanit Soc Sci Commun 12, 179 (2025). https://doi.org/10.1057/s41599-025-04465-z
-
Received: 31 May 2024
-
Accepted: 23 January 2025
-
Published: 10 February 2025
-
DOI: https://doi.org/10.1057/s41599-025-04465-z